I have data stored in a Snowflake table like the example below:
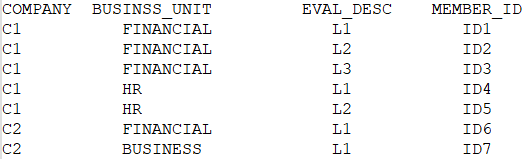
And now I wanted to create a CSV file in an S3 bucket using a Snowflake task.
This csv file should have the following format:

This is, the logic is (more or less) to transpose the table, having always a number of fixed columns (Company, Financial-L1, Financial-L2, Financial-L3, HR-L1, HR-L2) and in the case we do not have data for a given level then we use the member_id from the previous level (e.g. for C2 we do not have FINANCIAL-L2 or L3, so we picked the value from the FINANCIAL-L1).
V2:
Now I do not have EVAL_DESC, but I know that we have always 4 sub-levels inside each business unit and that the order the records appears are from top level hierarchy to down level hierarchy. And in the case we do not have records for all the 4 sub-levels of a depart we should use the member_id from the previous top level.
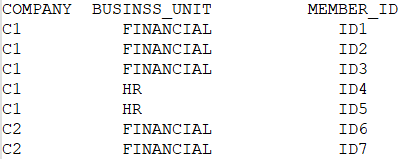
CSV Outpu:

How can I achieve this in the data transformation side?
CodePudding user response:
You can do transpose in snowflake as below; however as per your data-set it might include NULLs -
snowflake1#COMPUTE_WH@TEST_DB.PUBLIC>select * from (select company,concat(BU,'-',EVAL_DESC) as col1,member_id from TEST
_PIVOT) tab1 pivot(min(member_id) for col1 in ('FINANCIAL-L1','FINANCIAL-L2','FINA
NCIAL-L3','HR-L1','HR-L2','HR-L3','BUSINESS-L1','BUSINESS-L2','BUSINESS-L3')) as P
ORDER BY company;
--------- ---------------- ---------------- ---------------- --------- --------- --------- --------------- --------------- ---------------
| COMPANY | 'FINANCIAL-L1' | 'FINANCIAL-L2' | 'FINANCIAL-L3' | 'HR-L1' | 'HR-L2' | 'HR-L3' | 'BUSINESS-L1' | 'BUSINESS-L2' | 'BUSINESS-L3' |
|--------- ---------------- ---------------- ---------------- --------- --------- --------- --------------- --------------- ---------------|
| C1 | ID1 | ID2 | ID3 | ID4 | ID5 | NULL | NULL | NULL | NULL |
| C2 | ID6 | NULL | NULL | NULL | NULL | NULL | ID7 | NULL | NULL |
--------- ---------------- ---------------- ---------------- --------- --------- --------- --------------- --------------- ---------------
2 Row(s) produced. Time Elapsed: 0.307s
For treatment of NULLs you can adopt an apprach as below where in you specify columns names in select clause and use ifnull function - I have just selected a sub-set of columns, but same can be expanded to get entire data-set, you just need to put all column names manually
snowflake1#COMPUTE_WH@TEST_DB.PUBLIC>select company as comp, "'FINANCIAL-L2'" as f2 from (select company,concat(BU,'-',
EVAL_DESC) as col1,member_id from TEST_PIVOT) tab1 pivot(min(member_id) for col1 i
n ('FINANCIAL-L1','FINANCIAL-L2','FINANCIAL-L3','HR-L1','HR-L2','HR-L3','BUSINESS-
L1','BUSINESS-L2','BUSINESS-L3')) as P ORDER BY company;
------ ------
| COMP | F2 |
|------ ------|
| C1 | ID2 |
| C2 | NULL |
------ ------
2 Row(s) produced. Time Elapsed: 0.334s
This is the final result set with transpose and no NULLs -
snowflake1#COMPUTE_WH@TEST_DB.PUBLIC>select company as comp, ifnull("'FINANCIAL-L2'","'FINANCIAL-L1'") as f2 from (sele
ct company,concat(BU,'-',EVAL_DESC) as col1,member_id from TEST_PIVOT) tab1 pivot(
min(member_id) for col1 in ('FINANCIAL-L1','FINANCIAL-L2','FINANCIAL-L3','HR-L1','
HR-L2','HR-L3','BUSINESS-L1','BUSINESS-L2','BUSINESS-L3')) as P ORDER BY company;
------ -----
| COMP | F2 |
|------ -----|
| C1 | ID2 |
| C2 | ID6 |
------ -----
2 Row(s) produced. Time Elapsed: 0.313s
CodePudding user response:
Please try this. You see NULLs as there is no FINANCIAL, HR BU for C2, no BUSINESS BU for C1
SNOWFLAKE1#COMPUTE_WH@TEST_DB.PUBLIC>select * from test_pivot_1;
--------- ----------- -----------
| COMPANY | BU | MEMBER_ID |
|--------- ----------- -----------|
| C1 | FINANCIAL | ID1 |
| C1 | FINANCIAL | ID2 |
| C1 | FINANCIAL | ID3 |
| C1 | HR | ID4 |
| C1 | HR | ID5 |
| C2 | FINANCIAL | ID6 |
| C2 | BUSINESS | ID7 |
--------- ----------- -----------
7 Row(s) produced. Time Elapsed: 0.148s
SNOWFLAKE1#COMPUTE_WH@TEST_DB.PUBLIC>select company as comp,
ifnull("'FINANCIAL-L1'","'FINANCIAL-L2'") as "FINANCIAL-L1",
ifnull("'FINANCIAL-L2'","'FINANCIAL-L1'") as "FINANCIAL-L2",
ifnull("'FINANCIAL-L3'","'FINANCIAL-L1'") as "FINANCIAL-L2",
ifnull("'HR-L1'","'HR-L2'") as "HR-L1",
ifnull("'HR-L2'","'HR-L1'") as "HR-L2",
ifnull("'HR-L3'","'HR-L1'") as "HR-L3",
ifnull("'BUSINESS-L1'","'BUSINESS-L2'") as "BUSINESS-L1",
ifnull("'BUSINESS-L2'","'BUSINESS-L1'") as "BUSINESS-L2",
ifnull("'BUSINESS-L3'","'BUSINESS-L1'") as "BUSINESS-L3"
from
(select company,member_id,BU||'-'||'L'||row_number() over (partition by bu order b
y bu) as bu from TEST_PIVOT_1) tab1
pivot(min(member_id)
for BU
in ('FINANCIAL-L1','FINANCIAL-L2','FINANCIAL-L3','HR-L1','HR-L2','HR-L3','BUSINESS
-L1','BUSINESS-L2','BUSINESS-L3')) as P
ORDER BY company;
------ -------------- -------------- -------------- ------- ------- ------- ------------- ------------- -------------
| COMP | FINANCIAL-L1 | FINANCIAL-L2 | FINANCIAL-L2 | HR-L1 | HR-L2 | HR-L3 | BUSINESS-L1 | BUSINESS-L2 | BUSINESS-L3 |
|------ -------------- -------------- -------------- ------- ------- ------- ------------- ------------- -------------|
| C1 | ID1 | ID2 | ID3 | ID4 | ID5 | ID4 | NULL | NULL | NULL |
| C2 | NULL | NULL | NULL | NULL | NULL | NULL | ID7 | ID7 | ID7 |
------ -------------- -------------- -------------- ------- ------- ------- ------------- ------------- -------------
2 Row(s) produced. Time Elapsed: 0.166s
SNOWFLAKE1#COMPUTE_WH@TEST_DB.PUBLIC>