I have a dataframe like as shown below
ID,F1,F2,F3,F4,F5,F6,L1,L2,L3,L4,L5,L6
1,X,,X,,,X,A,B,C
1,X,,X,,,X,A,B,C
1,X,,X,,,X,A,B,C
2,X,,,X,,X,A,B,C,D,E
3,X,X,X,,,X,A
3,X,X,X,,,X,,B,,C
3,X,X,X,,,X,,D,C
4,X,X,,,,,A,B
4,,,,X,,X,G,H,I
4,,,X,,,,T
df = pd.read_clipboard(sep=',')
I would like to do the below
a) Remove full duplicates (where all values of each column match). ex: ID=1 (keep=first)
b) Collapse near duplicates into one row. ex: ID= 3 and 4. Near duplicates are rows where only ID match but rest of the F numbered and L number columns differ
I was trying the below but it results in incorrect output
The below code misses to copy other L numbered values which doesn't have NA before
df = df.drop_duplicates(keep='first') # this drops full duplicates ex:ID = 1
df.groupby(['ID'])['ID','F1','F2','F3','F4','F5','F6','L1','L2','L3','L4','L5','L6'].bfill().drop_duplicates(subset=['ID'],keep='first')
In real data, there are 50 F columns and 50 L columns. For F columns the position of X is important and has to be correct whereas for L columns, it can be anywhere as long as it is captured, it is fine.
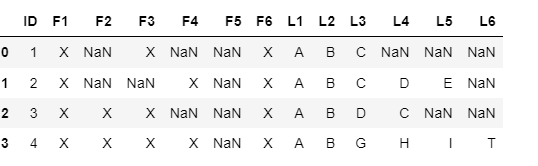
I expect my output to be like as shown below
CodePudding user response:
Use:
cL = df.filter(like='L').columns
cF = df.filter(like='F').columns
def f(x):
s = pd.Series(x.stack().unique()).rename(lambda x: f'L{x 1}')
print (s)
return s
#recreate L columns by remove missing values and duplicates
#f = lambda x: pd.Series(x.stack().unique()).rename(lambda x: f'L{x 1}')
df1 = df[cL].groupby(df['ID']).apply(f).unstack()
#remove original L columns
df = df.drop(cL, axis=1)
#for F columns processing with original solution
df[cF] = df.groupby(['ID'])[cF].bfill()
#after remove duplicates for F columns add L columns in df1
df = df.drop_duplicates(subset=['ID'],keep='first').join(df1, on='ID')
print (df)
ID F1 F2 F3 F4 F5 F6 L1 L2 L3 L4 L5 L6
0 1 X NaN X NaN NaN X A B C NaN NaN NaN
3 2 X NaN NaN X NaN X A B C D E NaN
4 3 X X X NaN NaN X A B C D NaN NaN
7 4 X X X X NaN X A B G H I T