I want to import a csv in Python with the following format:
with open('categories.csv', 'r') as file:
reader = csv.reader(file)
for row in reader:
print(row)
['id', 'categories']
['2', 'related-1;request-0;offer-0;aid_related-0;medical_help-0;medical_products-0;search_and_rescue-0;security-0;military-0;child_alone-0;water-0;food-0;shelter-0;clothing-0;money-0;missing_people-0;refugees-0;death-0;other_aid-0;infrastructure_related-0;transport-0;buildings-0;electricity-0;tools-0;hospitals-0;shops-0;aid_centers-0;other_infrastructure-0;weather_related-0;floods-0;storm-0;fire-0;earthquake-0;cold-0;other_weather-0;direct_report-0']
['7', 'related-1;request-0;offer-0;aid_related-1;medical_help-0;medical_products-0;search_and_rescue-0;security-0;military-0;child_alone-0;water-0;food-0;shelter-0;clothing-0;money-0;missing_people-0;refugees-0;death-0;other_aid-1;infrastructure_related-0;transport-0;buildings-0;electricity-0;tools-0;hospitals-0;shops-0;aid_centers-0;other_infrastructure-0;weather_related-1;floods-0;storm-1;fire-0;earthquake-0;cold-0;other_weather-0;direct_report-0']
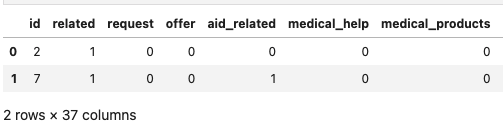
In the end, the dataframe should look like this:
ID related request ...
2 1 0 ...
7 1 0 ...
CodePudding user response:
You may consider using pandas:
import pandas
df = pd.read_csv('./text.csv')
# get and expand columns
columns = [i.split('-')[0] for i in df['categories'].str.split(';')[0]]
df[columns] = df['categories'].str.split(';', expand=True)
# drop categories column
df.drop('categories', axis=1, inplace=True)
# get value for each column
for column in columns:
df[column] = df[column].apply(lambda x : x.split('-')[1])
print(df)