I'd like to make a dataframe (?) which visually looks like the following:
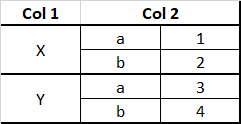
Is it possible using pandas? If so, can anyone suggest me related to that. If not, is that even possible to do in python? If possible, can anyone suggest me anything related to that?
CodePudding user response:
That exact layout is not possible in pandas because we need some way to programmatically access the values. Looking at your current table, how would we index the cell containing 2? It doesn't have a distinct index.
We can technically use MultiIndexes to wrap multiple rows/cols, but every individual row/col still needs a separate label, e.g.:
df = pd.DataFrame([['a', 1], ['b', 2], ['a', 3], ['b', 4]])
df.index = pd.MultiIndex.from_product([['Col1'], ['X', 'Y'], [0, 1]])
df.columns = pd.MultiIndex.from_product([['Col2'], [0, 1]])
# | Col2 |
# |-------|
# | 0 | 1 |
# -------------|---|---|
# Col1 | X | 0 | a | 1 |
# | |---|---|---|
# | | 1 | b | 2 |
# |---|---|---|---|
# | Y | 0 | a | 3 |
# | |---|---|---|
# | | 1 | b | 4 |
But this setup makes it really annoying to access values. For example, here we take a row cross-section at column 1 to access the cell containing 2:
df.xs(('Col1', 'X', 1))[1]
# 2
This is why we normally just use standard wide or long tables with simple row/col indexes, e.g.:
df = pd.DataFrame({'Col1': list('XXYY'), 'Col2_0': list('abab'), 'Col2_1': [1, 2, 3, 4]})
# Col1 Col2_0 Col2_1
# 0 X a 1
# 1 X b 2
# 2 Y a 3
# 3 Y b 4
df.loc[1, 'Col2_1']
# 2