I have a data frame as follows.
df_add = pd.DataFrame({
'unique_id':['a-1','a-2','a-3','a-4','a-5'],
'doc_id':[100,101,102,103,104],
'last_name':['Fernando','Fernando','Samba','Bhavik','Bhavik'],
'first_name':['Reich','Reich','Anil','Reich','Reich'],
'dob':['06-03-1900','06-03-1900','20-09-2020','09-16-2020','01-01-2021'],
'health':['Yes','','Yes','','Yes']
})
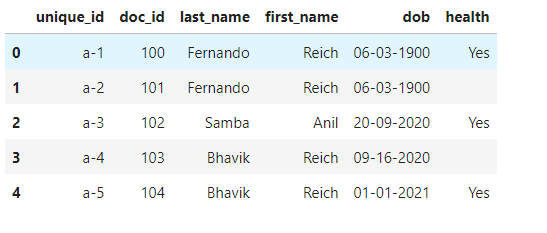
We can see that there are two persons records are duplicated considering last_name and first_name as below.
- Fernando Reich with same date of birth `06-03-1900’
- Bhavik Reich with two different dates of births as ‘09-16-2020’ and ‘01-01-2021’
In case of duplicate combinations of last_name and first roll up of these rows should be done with semicolon separator as below for example:
Case 1:
a-1 and a-2 records are duplicated on last and first name, so it should be rolled up and recorded as a single.
Dob is considered as UNIQUE since it is existed in both of 2 records.
a-1;a2 | 100;101 |Fernando |Reich |06-03-1900| Yes
Case 2:
a-4 and a-5 records are duplicated on last and first name, it should be records as a single. DOB’s are different for this person so they are separated with ;
a-4;a-5 |103;104 |Bhavik |Reich |09-16-2020;01-01-201 |Yes
Here the goal of this task is to remove duplicates and reduce the number of rows of a data frame, here is the expected output.
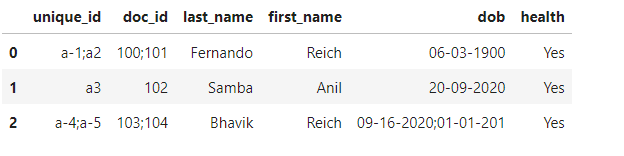
You can see that 5 rows are rolled up to 3 rows.
CodePudding user response:
You can use GroupBy.agg:
# function to aggregate as joined string without duplicates
# and maintaining original order
agg = lambda x: ';'.join(dict.fromkeys(map(str,x)))
out = (df_add
.groupby(['last_name', 'first_name'], as_index=False)
.agg({'unique_id': agg, 'doc_id': agg, 'dob': agg, 'health': 'max'})
)
Output:
last_name first_name unique_id doc_id dob health
0 Bhavik Reich a-4;a-5 103;104 09-16-2020;01-01-2021 Yes
1 Fernando Reich a-1;a-2 100;101 06-03-1900 Yes
2 Samba Anil a-3 102 20-09-2020 Yes