I have a data frame with three columns. The first one shows the users, the second one is date and the third one show the holiday or not. (1 is holiday and 0 is not holiday).
import pandas as pd
df = pd.DataFrame()
df['user'] = ['a', 'a', 'b','b', 'c', 'c', 'c']
df['date'] = ['2012-01-01', '2012-01-03', '2012-01-01','2012-01-02', '2012-01-01', '2012-01-02','2012-01-03']
df['holiday'] = [1, 0, 1, 0, 1,0, 0]
I want for each user and time, build two columns and then put them together, if a user have not a date, put 2 in that columns. For example, for user=a, we have two dates. Then, for this user I should build 1, 1, 2, 2, 0,0. Or, for user b, the rows is 1, 1, 0,0, 2,2.
For user a:
- date 2012-01-01, we have date and since it is holiday. Then we add two columns 1, 1.
- date 2012-01-02 : we dont have date, then we build two columns with 2,2.
- date 2012-01-03 : we have date and its not holiday, then we build two columns with 0,0.
For user b:
- date 2012-01-01, since it is holiday. Then we add two columns 1, 1.
- date 2012-01-02 : we have date, then we build two columns with 0,0.
- date 2012-01-03 : we dont have date. then we build two columns with 2,2.
For user c:
- date 2012-01-01, since it is holiday. Then we add two columns 1, 1.
- date 2012-01-02 : we have date, then we build two columns with 0,0.
- date 2012-01-03 : we have date, then we build two columns with 0,0.
Here is the dataframe which I want.
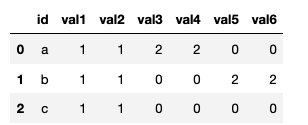
I've tried to use this code, but it gives me an error:
out = (df.reindex(df.index.repeat(2)).assign(col=lambda x: x.groupby('user').\
cumcount()).pivot_table( 'date', 'user', 'col', fill_value=2).add_prefix('val').rename_axis(index=None, columns=None))
CodePudding user response:
You can pivot, fillna, and then unstack twice:
tmp = df.pivot(index='date', columns='user', values='holiday').fillna(2).astype(int).unstack().unstack()
tmp = tmp[tmp.columns.repeat(2)]
# Formatting
tmp = tmp.set_axis(np.arange(tmp.shape[1]) 1, axis=1).add_prefix('val').reset_index()
Output:
user val1 val2 val3 val4 val5 val6
0 a 1 1 2 2 0 0
1 b 1 1 0 0 2 2
2 c 1 1 0 0 0 0