I have this situation that is as simple as it is annoying.
The requirements are
Every
itemmust have an associatedcategory.Every
itemMAY be included in aset.Setsmust be composed ofitemsof the samecategory.There may be several
setsof the same category.
The desired logic procedure to insert new data is as following:
Categoriesare inserted.Itemsare inserted. For each newitem, acategoryis assigned.Setsofitemsof the samecategoryare created.
I'd like to get a design where data integrity between tables is ensured.
I have come up with the following design, but I can't figure out how to maintain data integrity.
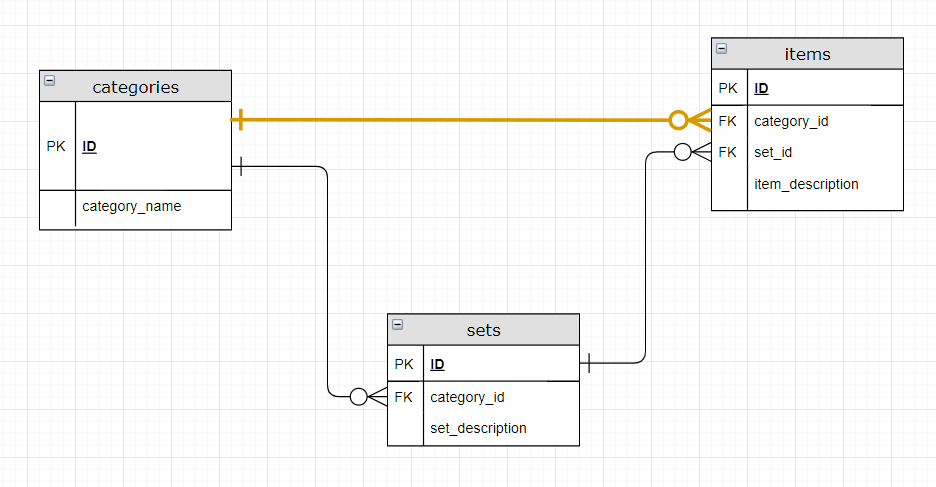
If the relationship highlighted in yellow is not taken into account, everything is very simple and data integrity is forced by design: an item acquires a category only when it is assigned to a set and the category is given by the set itself.However, it would not be possible to have items not associated with a set but linked to a category and this is annoying.
I want to avoid using special "bridging sets" to assign a category to an item since it would feel hacky and there is no way to distinguish between real sets and special ones.
So I introduced the relationship in yellow. But now you can create sets of objects of different categories!
How can I avoid this integrity problem using only plain constraints (index, uniques, FK) in MySQL?
Also I would like to avoid triggers as I don't like them as it seems a fragile and not very reliable way to solve this problem...
I've read about similar question like How to preserve data integrity in circular reference database structure? but I cannot understand how to apply the solution in my case...
CodePudding user response:
Interesting scenario. I don't see a slam-dunk 'best' approach. One consideration here is: what proportion of items are in sets vs attached only to categories?
What you don't want is two fields on
items. Because, as you say, there's going to be data anomalies: anitem's directcategorybeing different to thecategoryit inherits via itsset.Ideally you'd make a single field on
itemsthat is an Algebraic Data Type aka Tagged Union, with a tag saying its payload was acategoryvs aset. But SQL doesn't support ADTs. So any SQL approach would have to be a bit hacky.Then I suggest the compromise is to make every
itema member of aset, from which it inherits itscategory. Then data access is consistent: alwaysJOINitems-sets-categories.To support that, create dummy
setswhose only purpose is to link to acategory.To address "there is no way to distinguish between real sets and special ones": put an extra field/indicator on
sets: this is a 'real' set vs this is a link-to-category set. (Or a hack: make theset-descriptionas "Category: <category-name>".)
Addit: BTW your "desired logic procedure to insert new data" is just wrong: you must insert sets (Step 3) before items (Step 2).
CodePudding user response:
I think I might found a solution by looking at the answer from Roger Wolf to a similar situation here: Ensuring relationship integrity in a database modelling sets and subsets
Essentially, in the items table, I've changed the set_id FK to a composite FK that references both set.id and set.category_id from, respectively, items.set_id and item.category_id columns.
In this way there is an overlap of the two FKs on items table.
So for each row in items table, once a category_id is chosen, the FK referring to the sets table is forced to point to a set of the same category.
If this condition is not respected, an exception is thrown.
Now, the original answer came with an advice against the use of this approach. I am uncertain whether this is a good idea or not. Surely it works and I think that is a fairly elegant solution compared to the one that uses tiggers for such a simple piece of a a more complex design. Maybe the same solution is more difficult to understand and maintain if heavily applied to a large set of tables.