I have used below code to extract hashtags from tweets.
def find_tags(row_string):
tags = [x for x in row_string if x.startswith('#')]
return tags
df['split'] = df['text'].str.split(' ')
df['hashtags'] = df['split'].apply(lambda row : find_tags(row))
df['hashtags'] = df['hashtags'].apply(lambda x : str(x).replace('\\n', ',').replace('\\', '').replace("'", ""))
df.drop('split', axis=1, inplace=True)
df
However, when I am counting them using the below code I am getting output that is counting each character.
from collections import Counter
d = Counter(df.hashtags.sum())
data = pd.DataFrame([d]).T
data
Output I am getting is:
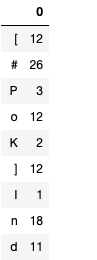
I think the problem lies with the code that I am using to extract hashtags. But I don't know how to solve this issue.
CodePudding user response:
Change find_tags by replace in list comprehension with split and for count values use Series.explode with Series.value_counts:
def find_tags(row_string):
return [x.replace('\\n', ',').replace('\\', '').replace("'", "")
for x in row_string.split() if x.startswith('#')]
df['hashtags'] = df['text'].apply(find_tags)
and then:
data = df.hashtags.explode().value_counts().rename_axis('val').reset_index(name='count')