for simplicity, lets say i have a dataframe the following arrangement:
import numpy as np
import pandas as pd
def random_dates(start, end, n, unit='D', seed=None):
if not seed:
np.random.seed(0)
ndays = (end - start).days 1
return pd.to_timedelta(np.random.rand(n) * ndays, unit=unit) start
np.random.seed(0)
start = pd.to_datetime('2015-01-01')
end = pd.to_datetime('2018-01-01')
date = random_dates(start, end, 1000)
#%%
gender = np.random.randint(0,2,(1000,))
DF = pd.DataFrame({'datetime_of_call':date,'gender_of_caller':gender})
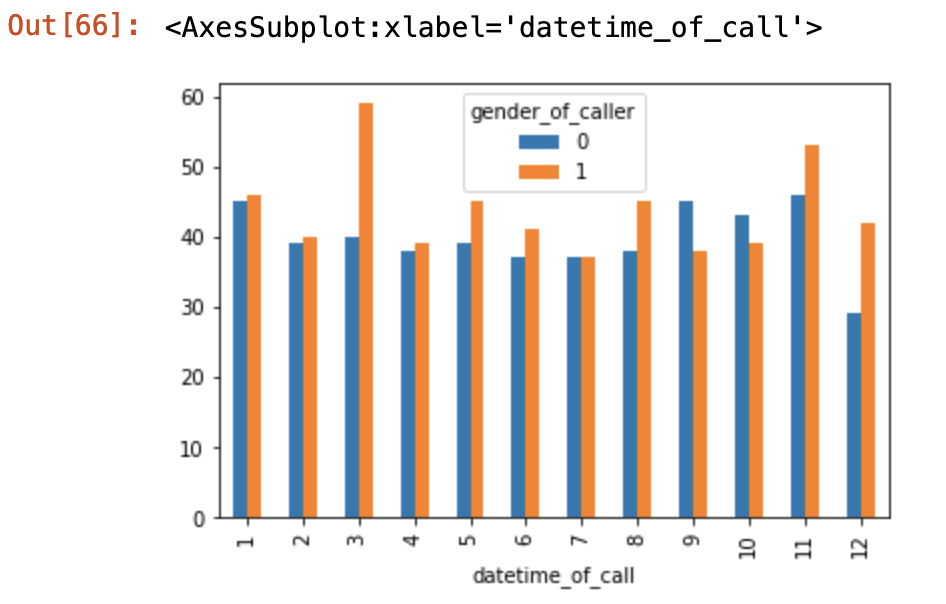
i want to plot the distribution of male and female callers to some line, as a function of year/month/hour ON TOTAL (separately, we can say just month for now)
for example, i want to see visually that irrespective of year, specifically on January there is a high fraction of female callers. another example would be if i want the frequency to be per hour, so i want to know the distribution of male/female throughout all years only by the hour.
i used grouper to group according to month:
DF.groupby(pd.Grouper(key='datetime_of_call',freq='M'))
now not sure how to continue, i tried the following:
pd.crosstab(DF.groupby(pd.Grouper(key='datetime_of_call',freq='M')),DF.gender_of_caller).plot.bar(stacked=True)
but got an error
ValueError: Shape of passed values is (37, 2), indices imply (1000, 2)
CodePudding user response:
I think you can achieve this with groupby and to_period
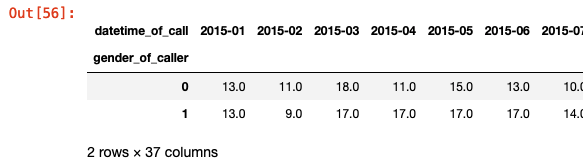
gb = DF.groupby(['gender_of_caller', DF.datetime_of_call.dt.to_period('M')]).size()
df = gb.unstack()
gets you a dataframe like:
Then you can take its transpose with
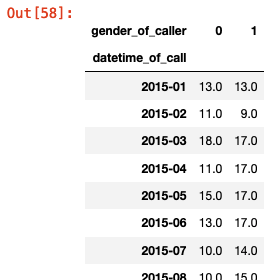
df = df.T
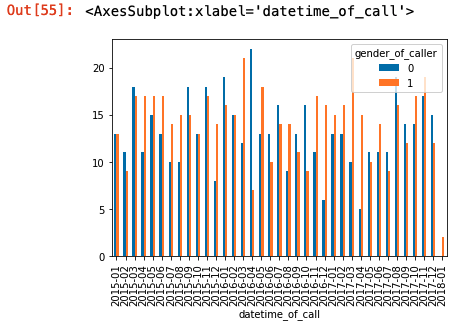
And then you can plot this as a bar chart or something:
df.plot(kind='bar')
EDIT: If you want the group by to be the month regardless of the year you can change the groupby line to:
gb = DF.groupby(['gender_of_caller', DF.datetime_of_call.dt.month]).size()
Now the final graph will look like: