I have two dataframes (df1, df2), df1 containing the student name, topic preference of each student, and df_topics containing topics.
Here is a sample input dataframe:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'Name':['student 1', 'student 2', 'student 3', 'student 4'],
'topics':['algebra; atom; geometry; evolution; food safety',
'chemical reaction; linear algebra; Probability; quantum',
'botany; electricity; mechanics',
'Statistics; botany; number theory; atom; evolution; Probability']})
df2 = pd.DataFrame({'topics':['algebra', 'Probability', 'geometry', 'atom', 'chemical reaction',
'evolution', 'botany', 'quantum'],
'cluster':[0, 0, 0, 1, 1, 2, 2, 3]
})

I want to represent each student by k (here k=4) dimensional binary vector, i.e. if the student has topics in df2, count topics are in each cluster and divide by a total number of topics for this student. for example, student 1 has two topics in cluster 0, algebra and geometry, which divide by 5 (total number of topics for student 1), we get 0.4 and etc.
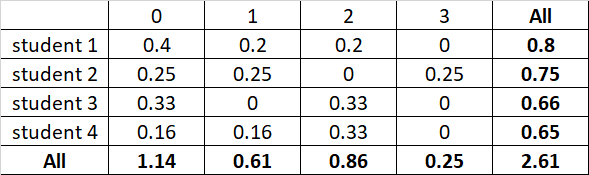
the results should look like this :
CodePudding user response:
There is probably a better way to achieve what you want but it should work:
out = (
df1.assign(topics=df1['topics'].str.split('; ')).explode('topics')
.merge(df2, how='left', on='topics')
.assign(size=lambda x: x.groupby('Name')['cluster'].transform('size'),
count=lambda x: x.groupby(['Name', 'cluster'])['cluster'].transform('count'),
ratio=lambda x: x['count'] / x['size'])
.query('cluster.notna()').astype({'cluster': int})
.drop_duplicates(['Name', 'cluster'])
.pivot_table('ratio', 'Name', 'cluster', aggfunc='sum', fill_value=0, margins=True)
.rename_axis(index=None, columns=None)
)
Output:
>>> out
0 1 2 3 All
student 1 0.400000 0.200000 0.200000 0.00 0.800000
student 2 0.250000 0.250000 0.000000 0.25 0.750000
student 3 0.000000 0.000000 0.333333 0.00 0.333333
student 4 0.166667 0.166667 0.333333 0.00 0.666667
All 0.816667 0.616667 0.866667 0.25 2.550000
CodePudding user response:
Explode df1 topics into one row per topic per student
df1 =df1.assign(topics=df1['topics'].str.split(';')).explode('topics')#Explode each topic into a row
Map df2 topics and clusters to df1
df1= df1.assign(topics=df1['topics'].str.strip().map(dict(zip(df2['topics'].str.strip(), df2['cluster'].astype(str)))).fillna('5'))
Compute the total count per row. You will notice I filled NaN with 5 to ensure where nothing was mapped ias also counted. Compute ratio per row
new =pd.crosstab(df1.Name, df1.topics).apply(lambda x:x/x.sum(),axis=1).drop(columns=['5'])#, margins_name="count").agg(lambda x:round(x/x['count'],1), axis=1).drop(columns=['5','count'])
#Sum row wise and column wise
#new['All'],new.loc['All']= new.sum(1),new.sum(0)
new['All']= new.sum(1)
new.loc['All']=new.sum(0)
print(new)
Output
topics 0 1 2 3 All
Name
student 1 0.400000 0.200000 0.200000 0.00 0.800000
student 2 0.250000 0.250000 0.000000 0.25 0.750000
student 3 0.000000 0.000000 0.333333 0.00 0.333333
student 4 0.166667 0.166667 0.333333 0.00 0.666667
All 0.816667 0.616667 0.866667 0.25 2.550000
CodePudding user response:
Here's an answer that delegates most of the work to a function named cluster() called via apply() for the student dataframe:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'Name':['student 1', 'student 2', 'student 3', 'student 4'],
'topics':['algebra; atom; geometry; evolution; food safety',
'chemical reaction; linear algebra; Probability; quantum',
'botany; electricity; mechanics',
'Statistics; botany; number theory; atom; evolution; Probability']})
df2 = pd.DataFrame({'topics':['algebra', 'Probability', 'geometry', 'atom', 'chemical reaction',
'evolution', 'botany', 'quantum'],
'cluster':[0, 0, 0, 1, 1, 2, 2, 3]
})
print(df1)
print('\n', df2)
clusterNames = df2['cluster'].unique().tolist() ['All']
clusters = [set(df2[df2['cluster'] == c]['topics']) for c in clusterNames[:-1]]
def cluster(x):
studentTopics = set(top.strip() for top in x['topics'].split(';'))
clusterPct = [len(clusterTopics & studentTopics) / len(studentTopics) for clusterTopics in clusters]
clusterPct = [sum(clusterPct)]
return clusterPct
df1[clusterNames] = df1.apply(cluster, axis=1).tolist()
df1 = pd.concat([df1.drop('topics', axis=1), pd.DataFrame([['All'] df1[clusterNames].sum(axis=0).tolist()], columns=['Name'] clusterNames)])
print('\n', df1)
Output:
Name topics
0 student 1 algebra; atom; geometry; evolution; food safety
1 student 2 chemical reaction; linear algebra; Probability...
2 student 3 botany; electricity; mechanics
3 student 4 Statistics; botany; number theory; atom; evolu...
topics cluster
0 algebra 0
1 Probability 0
2 geometry 0
3 atom 1
4 chemical reaction 1
5 evolution 2
6 botany 2
7 quantum 3
Name 0 1 2 3 All
0 student 1 0.400000 0.200000 0.200000 0.00 0.800000
1 student 2 0.250000 0.250000 0.000000 0.25 0.750000
2 student 3 0.000000 0.000000 0.333333 0.00 0.333333
3 student 4 0.166667 0.166667 0.333333 0.00 0.666667
0 All 0.816667 0.616667 0.866667 0.25 2.550000