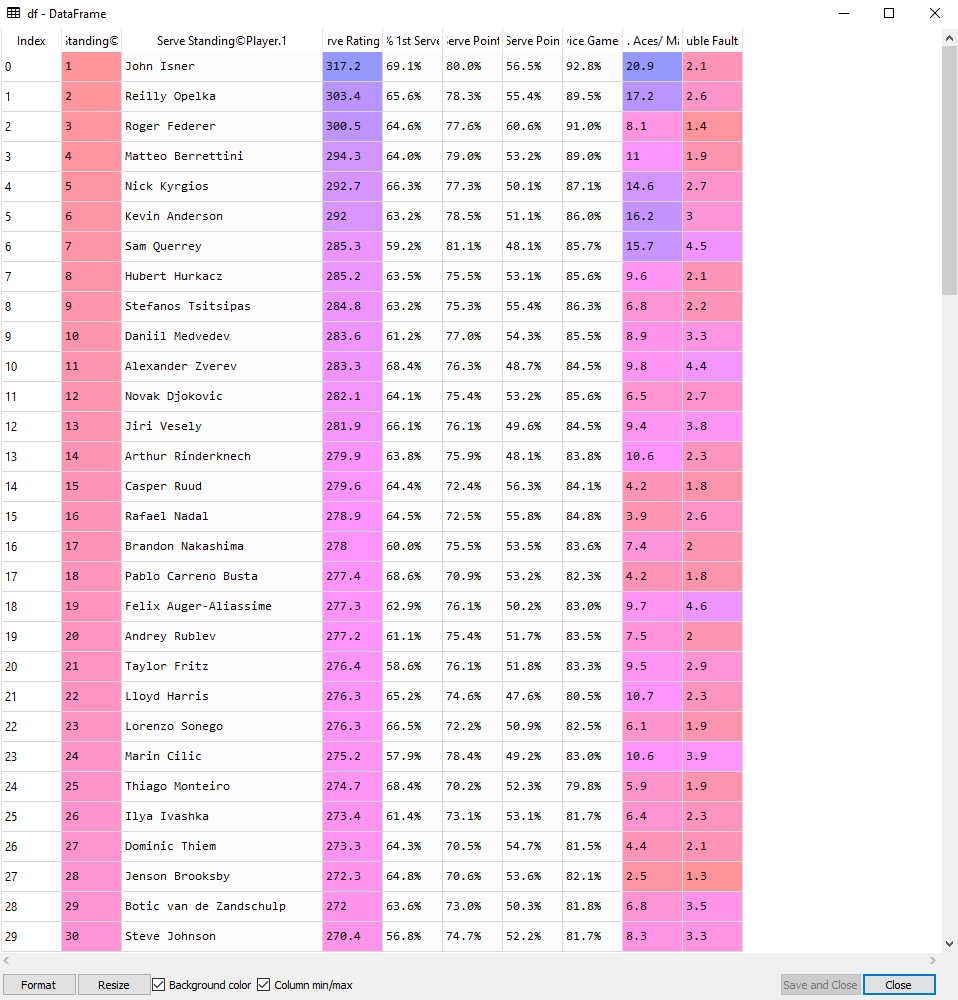
I am trying to webscrape the main table from this site: 
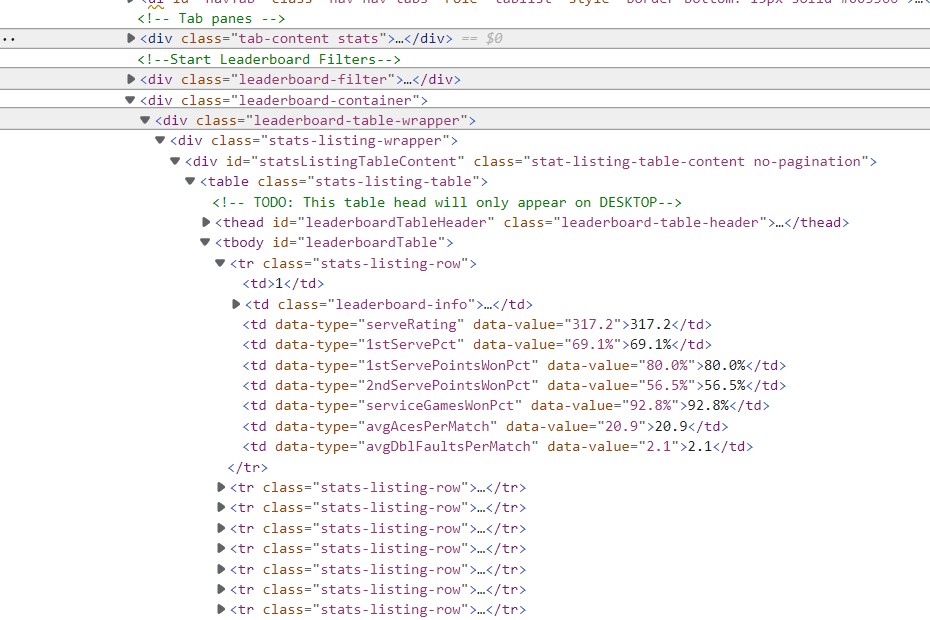
How do I access the rest of the html? It appears to not be there when I search through the soup. I have also attached an image of the html I am seeking to access. Any help is appreciated. Thank you!
CodePudding user response:
Your code is working as expected. The HTML you are parsing does not have any data under the table.
$ wget https://www.atptour.com/en/stats/leaderboard\?boardType\=serve\&timeFrame\=52Week\&surface\=all\&versusRank\=all\&formerNo1\=false -O page.html
$ grep -C 3 'leaderboardTable' page.html
>
<table >
<!-- TODO: This table head will only appear on DESKTOP-->
<thead id="leaderboardTableHeader" >
</thead>
<tbody id="leaderboardTable"></tbody>
</table>
</div>
You have shown a screenshot of the developer view that does contain the data. I would guess that there is a Javascript that modifies the HTML after it is loaded and puts in the rows. Your browser is able to run this Javascript, and hence you see the rows. requests of course doesn't run any scripts, it only downloads the HTML.
You can do "save as" in your browser to get the reuslting HTML, or you will have to use a more advanced web module such as Selenium that can run scripts.
CodePudding user response:
There is an ajax request that fetches that data, however it's blocked by cloudscraper. There is a package that can bypass that, however doesn't seem to work for this site.
What you'd need to do now, is use something like Selenium to allow the page to render first, then pull the data.
from selenium import webdriver
import pandas as pd
browser = webdriver.Chrome('C:/chromedriver_win32/chromedriver.exe')
browser.get("https://www.atptour.com/en/stats/leaderboard?boardType=serve&timeFrame=52Week&surface=all&versusRank=all&formerNo1=false")
df= pd.read_html(browser.page_source, header=0)[0]
browser.close()
Output: