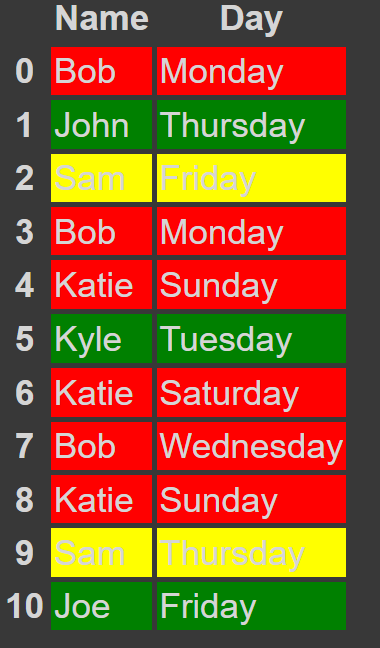
Using an example dataframe, df, as below:
| Name | Day |
|---|---|
| Bob | Monday |
| John | Thursday |
| Sam | Friday |
| Bob | Monday |
| Katie | Sunday |
| Kyle | Tuesday |
| Katie | Saturday |
| Bob | Wednesday |
| Katie | Sunday |
| Sam | Thursday |
| Joe | Friday |
What I want to do is to highlight a row say yellow if the value in the Name column only appears once and then say red if the value appears twice.
What I tried to do was group them by name and then do something like the following to highlight the rows with names that appeared once:
highlight = lambda x: ['background: yellow' if (x['Name'] != (x-1)['Name'] and x['Name'] != (x 1)['Name']) else '' for i in x]
df.style.apply(highlight, axis = 1)
However, this didn't work so I didn't get onto trying to highlight the rows with values in the name column that appeared twice. Despite trying to research it I don't fully understand how lambda x works so I don't know if you can apply an operator to access a previous row.
Edit:
In line with the recommended question I've tried the following:
def color_recommend():
for index, row in enumerate(df):
if df.Name.str.count(df.loc[i, 'Name']).sum() == 1:
color = 'red'
elif df.Name.str.count(df.loc[i, 'Name']).sum() == 2:
color = 'green'
else:
color = 'white'
return 'background-color: %s' % color
df.style.applymap(color_recommend)
But its still not working for me. I'm not sure what I'm missing here.
CodePudding user response:
First create a dictionary containing the mapping of counts->color, then use value_counts to calculate the frequency of each string appearing in the Name column, then map the calculated frequency with the cmap dictionary to create colors, finally apply colors on each column to get the result
cmap = {1: 'green', 2: 'yellow', 3: 'red'}
freq = df['Name'].map(df['Name'].value_counts())
colors = freq.map(cmap).radd('background-color: ')
df.style.apply(lambda s: colors)
Result