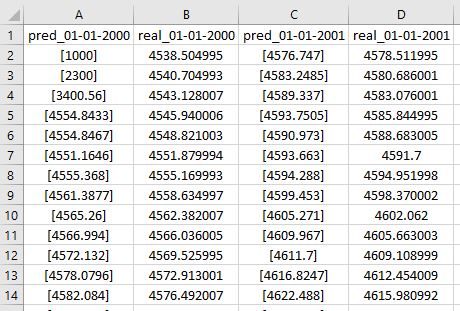
I have several large csv filess each 100 columns and 800k rows. Starting from the first column, every other column has cells that are like python list, for example: in cell A2, I have [1000], in cell A3: I have [2300], and so forth. Column 2 is fine and are numbers, but columns 1, 3, 5, 7, etc, ...99 are similar to the column 1, their values are inside list. Is there an efficient way to remove the sign of the list [] from those columns and make their cells like normal numbers?
files_directory: r":D\my_files"
dir_files =os.listdir(r"D:\my_files")
for file in dir_files:
edited_csv = pd.read_csv("%s\%s"%(files_directory, file))
for column in list(edited_csv.columns):
if (column % 2) != 0:
edited_csv[column] = ?
CodePudding user response:
When reading the cells, for example column_1[3], which in this case is [4554.8433], python will read them as arrays. To read the numerical value inside the array, simply read the values like so:
value = column_1[3]
print(value[0]) #prints 4554.8433 instead of [4554.8433]
CodePudding user response:
Please try:
import pandas as pd
df = pd.read_csv('file.csv', header=None)
df.columns = df.iloc[0]
df = df[1:]
for x in df.columns[::2]:
df[x] = df[x].apply(lambda x: float(x[1:-1]))
print(df)