I am trying to get a count of the most occurring words in my df, grouped by another Columns values:
I have a dataframe like so:
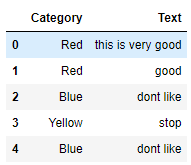
df=pd.DataFrame({'Category':['Red','Red','Blue','Yellow','Blue'],'Text':['this is very good ','good','dont like','stop','dont like']})
This is the way that I have counted the keywords in the Text column:
from collections import Counter
top_N = 100
stopwords = nltk.corpus.stopwords.words('english')
# # RegEx for stopwords
RE_stopwords = r'\b(?:{})\b'.format('|'.join(stopwords))
# replace '|'-->' ' and drop all stopwords
words = (df.Text
.str.lower()
.replace([r'\|', RE_stopwords], [' ', ''], regex=True)
.str.cat(sep=' ')
.split()
)
# generate DF out of Counter
df_top_words = pd.DataFrame(Counter(words).most_common(top_N),
columns=['Word', 'Frequency']).set_index('Word')
print(df_top_words)
Which produces this result:

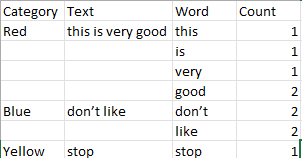
However this just generates a list of all of the words in the data frame, what I am after is something along the lines of this:
CodePudding user response:
Your words statement finds the words that you care about (removing stopwords) in the text of the whole column. We can change that a bit to apply the replacement on each row instead:
df["Text"] = (
df["Text"]
.str.lower()
.replace([r'\|', RE_stopwords], [' ', ''], regex=True)
.str.strip()
# .str.cat(sep=' ')
.str.split() # Previously .split()
)
Resulting in:
Category Text
0 Red [good]
1 Red [good]
2 Blue [dont, like]
3 Yellow [stop]
4 Blue [dont, like]
Now, we can use .explode and then .groupby and .size to expand each list element to its own row and then count how many times does a word appear in the text of each (original) row:
df.explode("Text").groupby(["Category", "Text"]).size()
Resulting in:
Category Text
Blue dont 2
like 2
Red good 2
Yellow stop 1
Now, this does not match your output sample because in that sample you're not applying the .replace step from the original words statement (now used to calculate the new value of the "Text" column). If you wanted that result, you just have to comment out that .replace line (but I guess that's the whole point of this question)