I have a table with 2 columns: an id and an associated label. Example:
id1,label1
id1,null
id2,label2
id3,null
I would like to deduplicate on the 1st column to keep the version where the label column is not null. But if the id appears only once, I want to keep the line no matter what, even though the label is null. The output I would want with the example is:
id1,label1
id2,label2
id3,null
How can I do this ?
CodePudding user response:
Consider below (BigQuery)
select *
from your_table
qualify 1 = row_number() over(partition by id order by label desc)
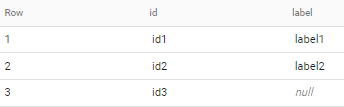
if applied to sample data in your question - output is
CodePudding user response:
delete
from <table1> d1
where d1.label is null
and exists ( select null
from <table1> d2
where d2.id = d1.id
and d2.label is not null
) ;
EXISTS always returns True or False if the subslect would have returned at least 1 row. In this case it returns True only when there is a matching row where label is not null.
Note: This does not work where there are multiple id each having a non-null label nor each having a null label. So would not work on tuples
('a',null) with ('a',null) nor the tuples
('a','l1') with ('a','l1')