I want to get P95 value of a column after groupBy, but when I check the result, I find that the P95 value is greater than the max value. My usage is as follows:
from pyspark.sql.types import StructType, StructField, StringType, LongType, FloatType
instance_util_schema = StructType([StructField("namespace", StringType(), True),
StructField("metricname", StringType(), True),
StructField("instance_id", StringType(), True),
StructField("time", LongType(), True),
StructField("maxvalue", FloatType(), True),
StructField("minvalue", FloatType(), True),
StructField("meanvalue", FloatType(), True),
StructField("sumvalue", FloatType(), True),
StructField("number", LongType(), True),
StructField("region", StringType(), True),
StructField("date", StringType(), True)
])
df = spark.read.csv("xxxx", header=True)
df = df.drop('minvalue', 'meanvalue', 'sumvalue', 'number')
df = df.withColumn("ts", from_unixtime(df['time'] / 1000)) \
.withColumn("year", date_format("ts", "yyyy")) \
.withColumn("month", date_format("ts", "MM")) \
.withColumn("day", date_format("ts", "dd")) \
.withColumn("hour", date_format("ts", "HH"))
dfg = df.groupBy("instance_id","year","month", "day", "hour").agg(
F.min('time').alias("timestamp"),
F.max(F.col('maxvalue')).alias('max'),
F.percentile_approx(F.col('maxvalue'), 0.95).alias('p95'),
F.percentile_approx(F.col('maxvalue'), 0.90).alias('p90'),
F.percentile_approx(F.col('maxvalue'), 0.50).alias('p50'),
F.percentile_approx(F.col('maxvalue'), 0.05).alias('p5'),
F.min('maxvalue').alias('min')
)
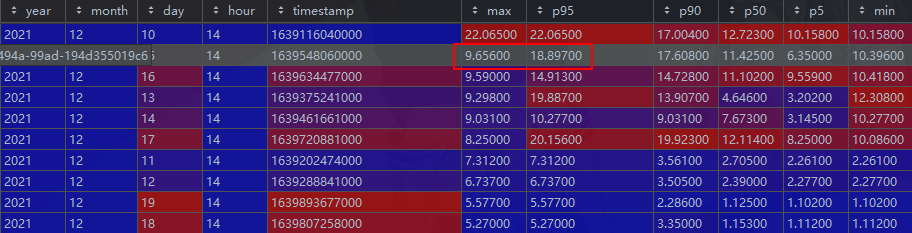
Now I use this to handle this problem, but I still don't know the reason.
dfg = df.withColumn('maxvalue', F.col('maxvalue').cast(FloatType())).groupBy(
"instance_id", "year", "month", "day", "hour").agg(
F.min('time').alias("timestamp"),
F.max(F.col('maxvalue')).alias('max'),
F.expr("percentile(maxvalue, 0.95)").alias('p95'),
F.expr("percentile(maxvalue, 0.90)").alias('p90'),
F.expr("percentile(maxvalue, 0.50)").alias('p50'),
F.expr("percentile(maxvalue, 0.05)").alias('p5'),
F.min('maxvalue').alias('min'))
CodePudding user response:
It's not because of percentile_approx. It's because your "maxvalue" column is actually not of float type. In your fixed code, the type of this column was changed to float, so then it worked fine. In such case, when numbers are given as strings, percentiles are calculated correctly, but min and max values are incorrect.
df = spark.createDataFrame([("9.65600",), ("18.89700",), ("10.39600",)], ["maxvalue"])
dfg = df.groupBy().agg(
F.max(F.col('maxvalue')).alias('max'),
F.percentile_approx(F.col('maxvalue'), 0.95).alias('p95'),
F.percentile_approx(F.col('maxvalue'), 0.90).alias('p90'),
F.percentile_approx(F.col('maxvalue'), 0.50).alias('p50'),
F.percentile_approx(F.col('maxvalue'), 0.05).alias('p5'),
F.min('maxvalue').alias('min')
)
dfg.show()
# ------- ------ ------ ------ ----- --------
#| max| p95| p90| p50| p5| min|
# ------- ------ ------ ------ ----- --------
#|9.65600|18.897|18.897|10.396|9.656|10.39600|
# ------- ------ ------ ------ ----- --------