Let's say we are designing core functionality of dropbox which is backed by Amazon S3. I have few confusions regarding how the upload works (as below is my assumption of the upload work flow. Please correct me if any step below is wrong)
- user contacts the application server at dropbox that I have a file of 1GB that needs to be uploaded.
- Dropbox provide a preSigned S3 URL to the user instructing to upload the file directly to S3 using resumable (multipart) upload.
- So now S3 has got the file chunked into lets say 10 parts.
Q1. If my understanding till now is correct then who re-assembles the file on the on the S3 to create the 1GB file?
Q2. If file is not re-assembled and kept in chunks does S3 inform dropbox that here is the list of chunks and their location so dropbox can store that information in its metadata tables?
Q3. If file is re-assembled but we WANT to store it in the chunk format then does it mean the upload needs to happen through dropbox ( using some upload service where we can store the chunks in S3 and store the metadata in our table)?
Note: I have read quite a lot of resource on this and the system diagram of file upload is bit inconsistent. At some place file upload process is carried out through block servers sitting behind our(dropbox) Load balancer.
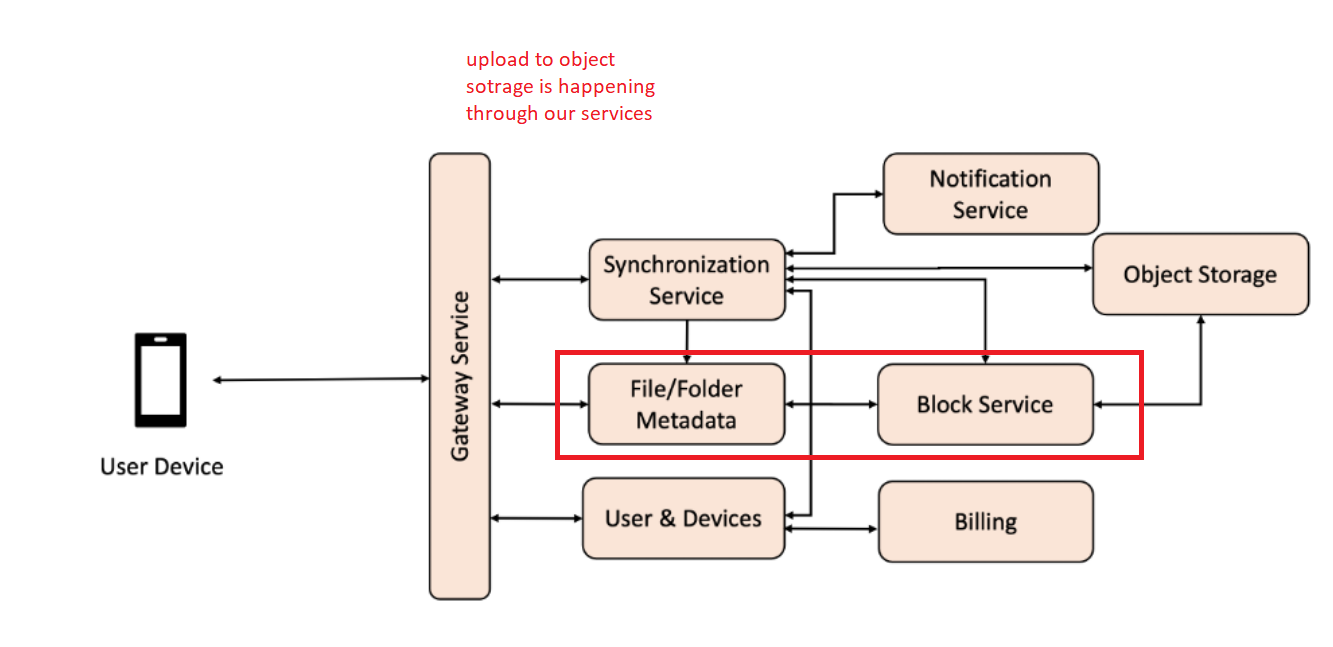
And in some place file is uploaded directly to s3.
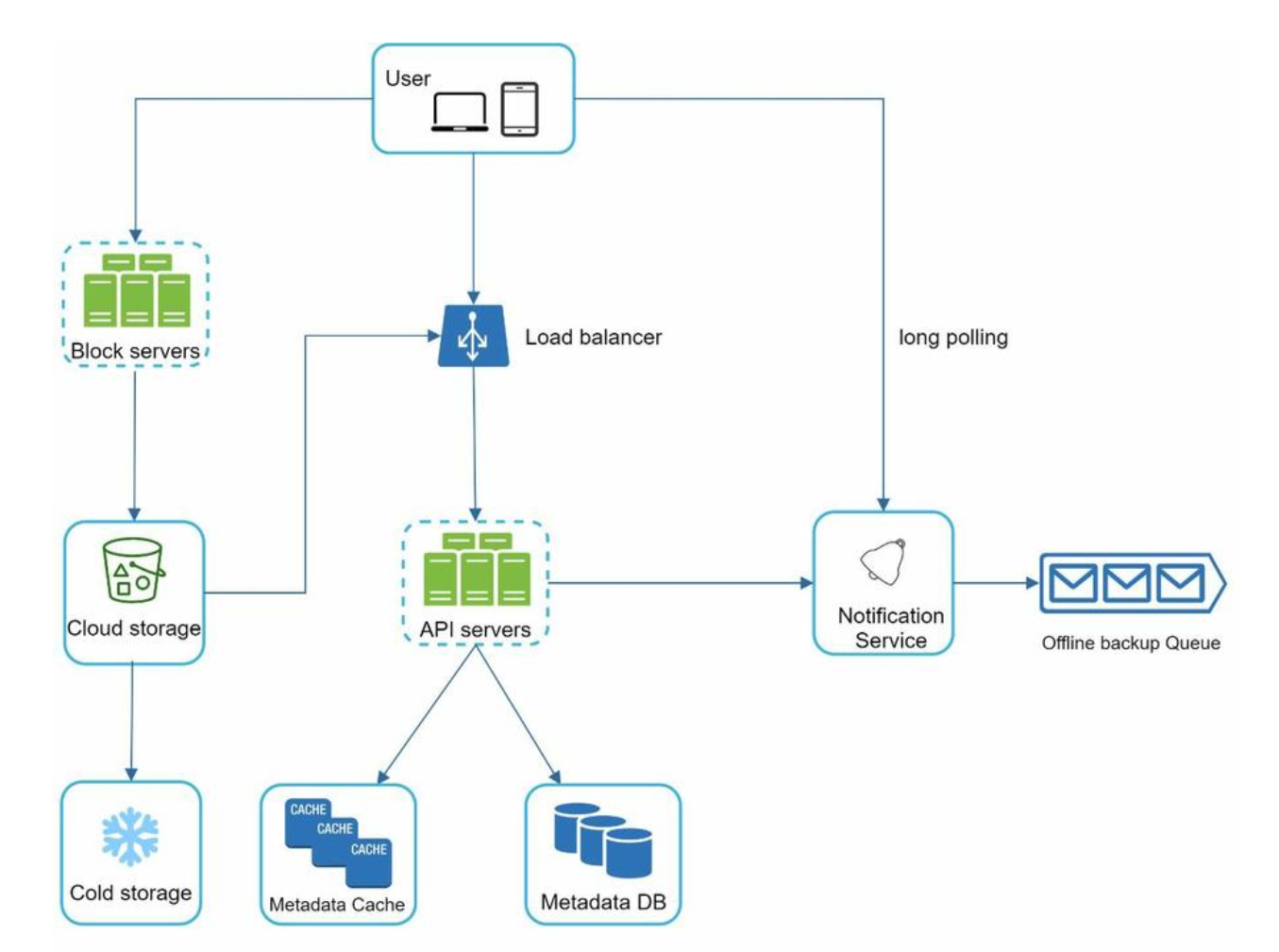
CodePudding user response:
Q1 & Q3
If you chunk the file, and upload them using the normal PutObject API, then they remain chunked.
If you chunk the file, and upload them using the multipart upload sequence (CreateMultipartUpload, UploadPart, then CompleteMultipartUpload), then S3 will re-assemble the file. Refer to the API reference.
Q2
So if you use the multipart upload sequence, but leave it hanging there by not successfully calling the CompleteMultipartUpload, then they will just be left hanging there. You will be billed though, so it is your responsibility to keep track of these. S3 will not inform you.
Note
The diagrams are irrelevant in this case.