I'm using scrapy to extract movie titles in html like this below:
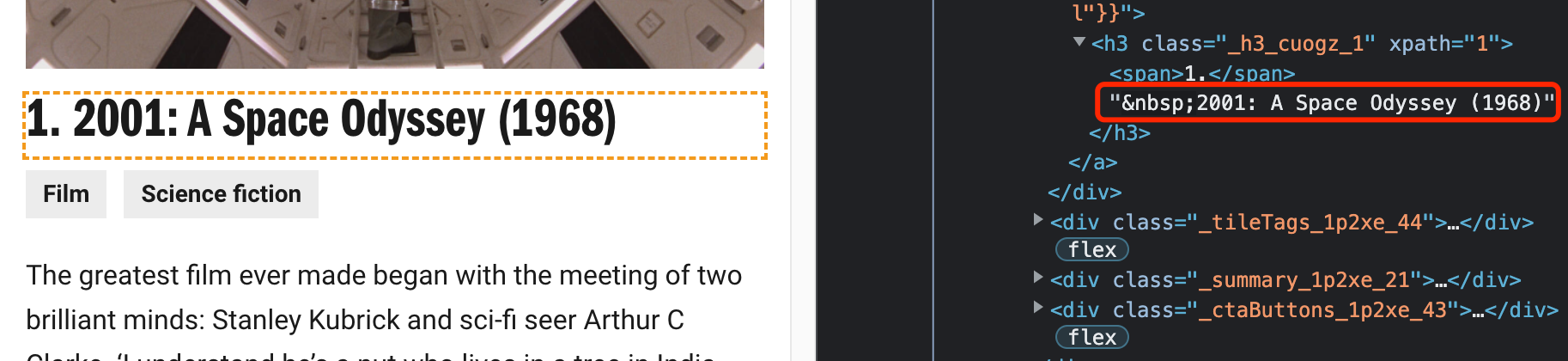
I copied xpath from the browser console(F12), it's:
//*[@id="main-container"]/main/div[1]/section[1]/div[3]/div[1]/article[1]/div[2]/div[1]/a/h3/text()
my scrapy code is:
import scrapy
class MmSpider(scrapy.Spider):
name = 'name'
start_urls = [
'https://www.timeout.com/film/best-movies-of-all-time'
]
def parse(self, response):
response.xpath('/html/body/div[5]/main/div[1]/section[1]/div[3]/div[1]/article[1]/div[2]/div[1]/a/h3/text()').get()
then use this command to run it:
scrapy runspider mmspider.py -o mm.jl
but mm.jl file is empty, is there any problem with my code or xpath?
CodePudding user response:
Your code is okey but xpath selection was incorrect.You can follow the next example how to grab title using xpath.
import scrapy
from scrapy.crawler import CrawlerProcess
class MmSpider(scrapy.Spider):
name = 'name'
start_urls = ['https://www.timeout.com/film/best-movies-of-all-time']
def parse(self, response):
for title in response.xpath('//h3[@]'):
yield {
'title':title.xpath('.//text()').getall()[-1].replace('\xa0','')
}
if __name__ == "__main__":
process = CrawlerProcess()
process.crawl(MmSpider)
process.start()
Output:
{'title': '2001: A Space Odyssey (1968)'}
2022-04-12 15:17:36 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.timeout.com/film/best-movies-of-all-time>
{'title': 'The Godfather (1972)'}
2022-04-12 15:17:36 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.timeout.com/film/best-movies-of-all-time>
{'title': 'Citizen Kane (1941)'}
2022-04-12 15:17:36 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.timeout.com/film/best-movies-of-all-time>
{'title': 'Jeanne Dielman, 23, Quai du Commerce, 1080 Bruxelles (1975)'}
2022-04-12 15:17:36 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.timeout.com/film/best-movies-of-all-time>
{'title': 'Raiders of the Lost Ark (1981)'}
2022-04-12 15:17:36 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.timeout.com/film/best-movies-of-all-time>
{'title': 'La Dolce Vita (1960)'}
2022-04-12 15:17:36 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.timeout.com/film/best-movies-of-all-time>
{'title': 'Seven Samurai (1954)'}
2022-04-12 15:17:36 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.timeout.com/film/best-movies-of-all-time>
{'title': 'In the Mood for Love (2000)'}
2022-04-12 15:17:36 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.timeout.com/film/best-movies-of-all-time>
{'title': 'There Will Be Blood (2007)'}
... so on