I am training a BDT using XGBoost to do binary classification on 22 features. I have 18 Million Samples. (60% for training, 40% for testing)
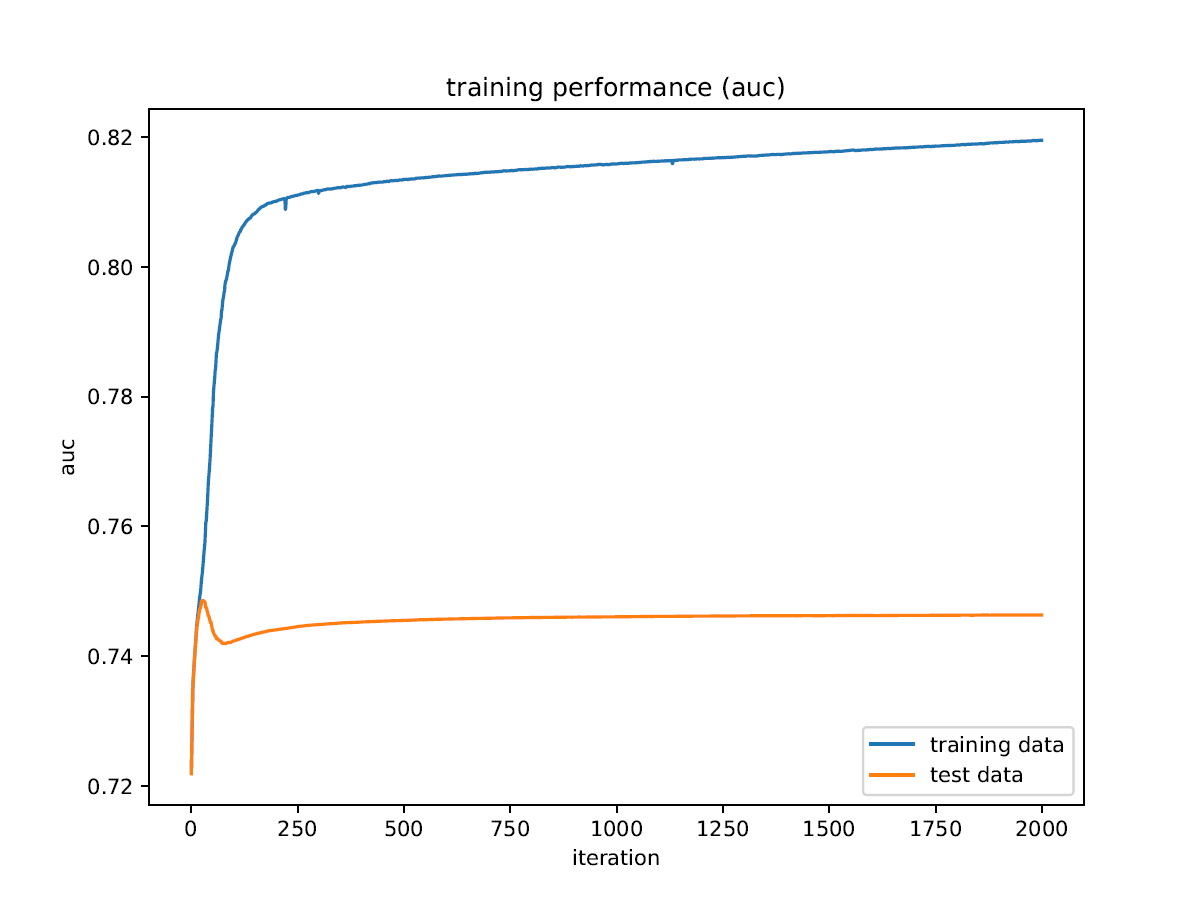
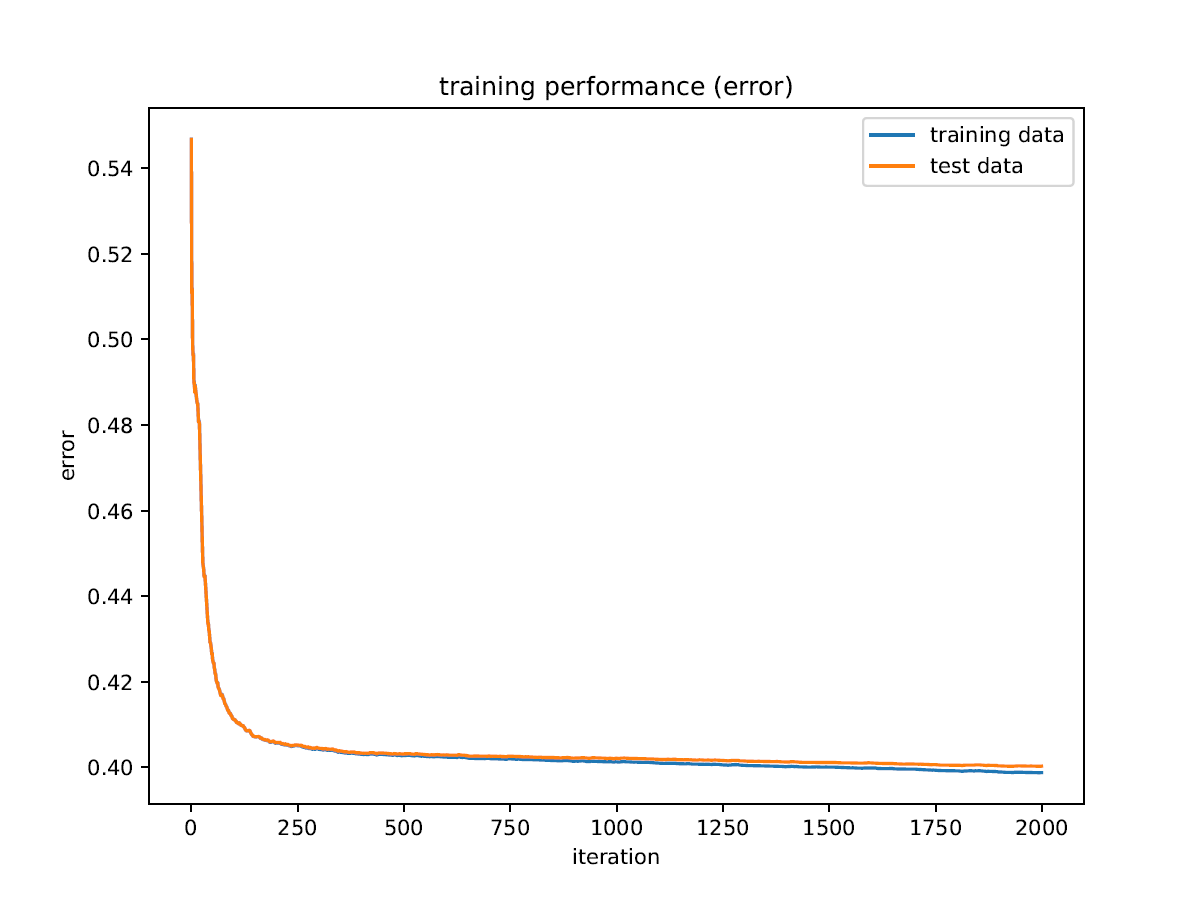
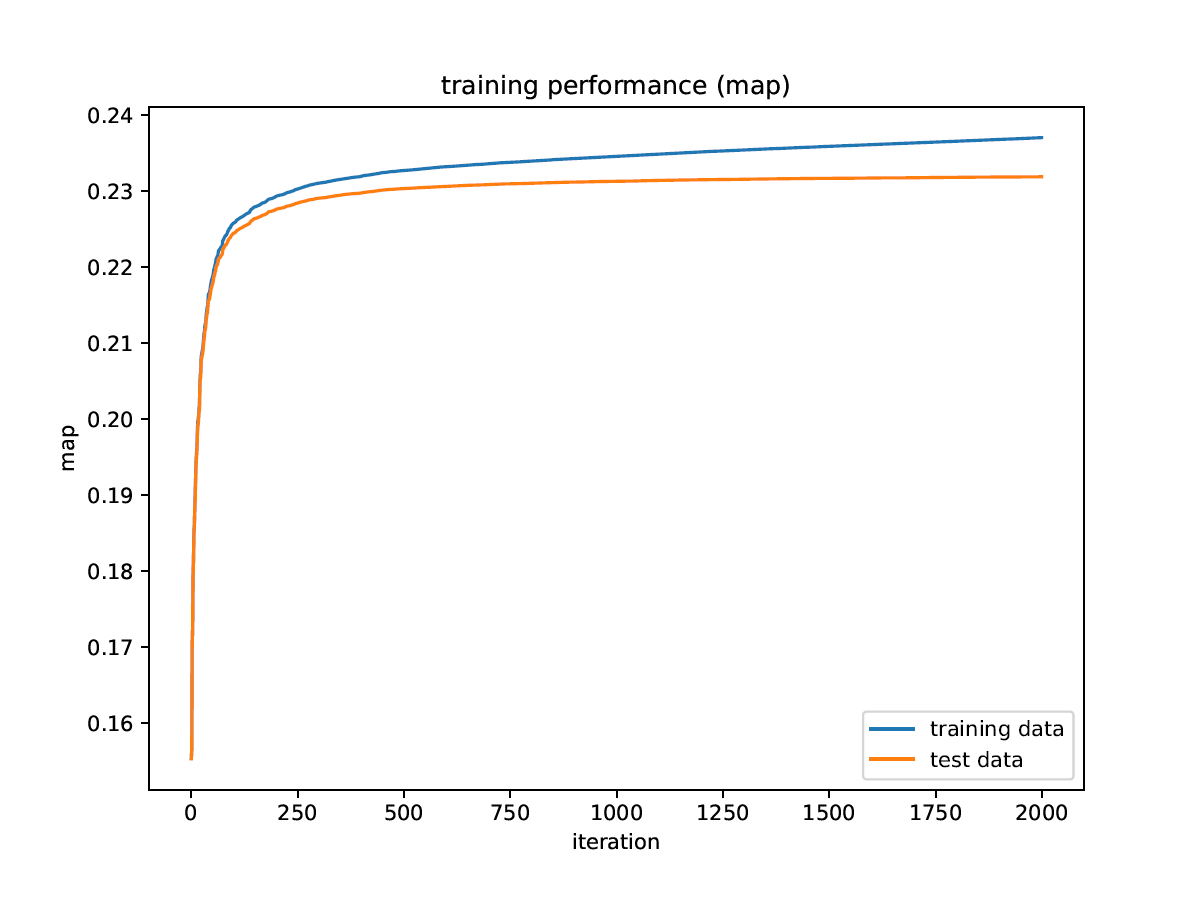
The ROC AUC I get during training does not fit the end result I get, and I do not understand how this can be. Also, the ROC AUC shows way more overtraining than any other metric, and it appears to have a maximum on the test data.
Has anyone encountered a similar problem before, or has any idea what's wrong with my model, or how I can find out what's wrong?
The essence of my code:
params = {
"model_params": {
"n_estimators": 2000,
"max_depth": 4,
"learning_rate": 0.1,
"scale_pos_weight": 11.986832275943744,
"objective": "binary:logistic",
"tree_method": "hist"
},
"train_params": {
"eval_metric": [
"logloss",
"error",
"auc",
"aucpr",
"map"
]
}
}
model = xgb.XGBClassifier(**params["model_params"], use_label_encoder=False)
model.fit(X_train, y_train,
eval_set=[(X_train, y_train), (X_test, y_test)],
**params["train_params"])
train_history = model.evals_result()
...
plt.plot(iterations, train_history["validation_0"]["auc"], label="training data")
plt.plot(iterations, train_history["validation_1"]["auc"], label="test data")
...
y_pred_proba_train = model.predict_proba(X_train)
y_pred_proba_test = model.predict_proba(X_test)
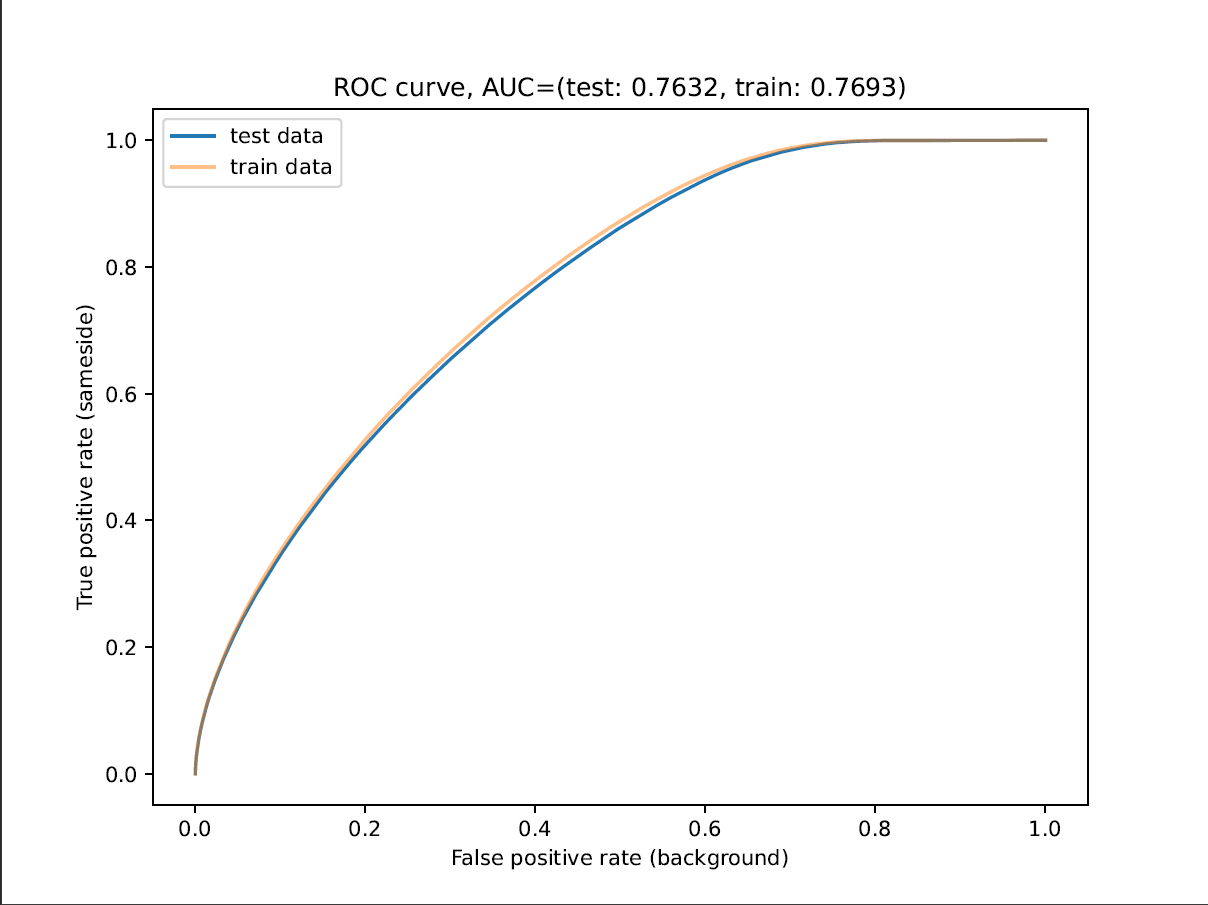
fpr_test, tpr_test, _ = sklearn.metrics.roc_curve(y_test, y_pred_proba_test[:, 1])
fpr_train, tpr_train, _ = sklearn.metrics.roc_curve(y_train, y_pred_proba_train[:, 1])
auc_test = sklearn.metrics.auc(fpr_test, tpr_test)
auc_train = sklearn.metrics.auc(fpr_train, tpr_train)
...
plt.title(f"ROC curve, AUC=(test: {auc_test:.4f}, train: {auc_train:.4f})")
plt.plot(fpr_test, tpr_test, label="test data")
plt.plot(fpr_train, tpr_train, label="train data")
...
CodePudding user response:
It's not clear in the documentation, but when a validation set is provided, XGBoost may use the model state of the iteration with the best validation metrics (in your case, map) for predictions when using the scikit-learn API.
You aren't doing anything wrong; it's completely normal for a GBT to overfit when allowed to train for many iterations.
Edit: This doesn't explain it; as per the updated OP, the validation map continued to improve over ever iteration.
CodePudding user response:
When training on a cluster, XGBoost calculates the AUC (ctrl-f for 'auc') as a macro average over each node. Particularly given your class imbalance, I suspect this is the culprit.