Below is the reproducible code
colo = ['red', 'red', 'red','cross','cross','red', 'red', 'red','cross','cross','cross',
'cross','cross', 'red', 'red','cross', 'red','cross','cross']
dt = pd.DataFrame()
dt['seq']=[i for i in range(len(colo))]
dt['col'] = colo
Expected Output:
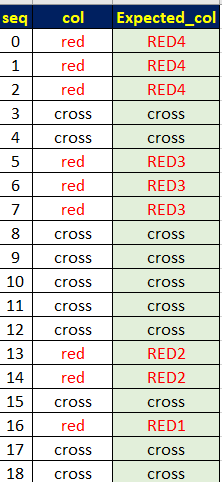
The column seq and col is been given & Expected_col is required to be created.
CodePudding user response:
Here's one way using eq diff ne cumsum to greate groups; then use boolean indexing to fill in values:
cond = dt['col'].eq('red')
s = dt.loc[cond, 'seq'].diff().ne(1).cumsum()
dt['Expected_col'] = dt['col']
dt.loc[cond, 'Expected_col'] = 'RED' (s.max() 1 - s).astype(str)
Output:
seq col Expected_col
0 0 red RED4
1 1 red RED4
2 2 red RED4
3 3 cross cross
4 4 cross cross
5 5 red RED3
6 6 red RED3
7 7 red RED3
8 8 cross cross
9 9 cross cross
10 10 cross cross
11 11 cross cross
12 12 cross cross
13 13 red RED2
14 14 red RED2
15 15 cross cross
16 16 red RED1
17 17 cross cross
18 18 cross cross