I have a dataset of n samples and 6 attributes and two classes.
I am currently using the KNeighborsClassifier from Scikit Learn in order to classify a dataset's two classes.
I am looking to plot the values of the dataset (across an arbitrary two attributes/domains of the dataset) and would look the plot to show the split according to the KNeighborsClassifier that I have. In other words, to plot the values and have the background sections of the plot match what the classification would be. So for example, Class 1 would be blue and Class 2 would be red. The points in those areas would have the appropriate color and the background (containing points are not) would have the appropriate color as well.
However, I can't seem to find help online on how I can achieve this. Any help would be appreciated.
CodePudding user response:
Plot two sets of points. For example, assuming that:
- There are two features (columns) in your data.
- The class labels are integers.
- The validation or test data are called
X_testandy_test, and the predictions are calledy_pred.
You can do something like this:
plt.scatter(*X_test.T, c=y_test, size=80, cmap='bwr', alpha=0.5)
plt.scatter(*X_test.T, c=y_pred, size=30, cmap='bwr')
This plots the actual labels in a larger size (so you can see them sticking out from behind the predictions), and with half opacity (i.e. semi-transparent).
If your labels are strings (like 'A' and 'B') you'll have to encode them to use this approach (or just use something like c=y_test=='A' and c=y_pred=='A' in the two plot commands). You might also need to adjust sizes to work for you.
CodePudding user response:
If you're trying to make a plot like 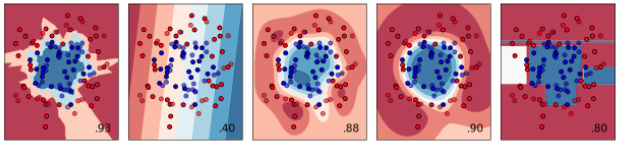
...then you're in luck because that page includes al lthe code you need to make that plot.
The keys part is this:
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Here, they are making a grid of coordinates representing a fake dataset covering the space you see in the plot. Essentially, you're making a new X that is a regular grid of data.
Then you classify those points using either the predict or predict_proba method on the classifier. These need to be reshaped into the grid shape:
Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]
Z = Z.reshape(xx.shape)
Then you can look at Z with something like plt.imshow(Z).