The code runs fine and even loops through all the pages, but the problem is that it does not stop at the last page. From 15 page onwards it runs in a continuous loop that is page 15 , page 16 again page 15 and page 16 and so on
from bs4 import BeautifulSoup as soup
import pandas as pd
import requests
import urllib
import requests, random
data =[]
def getdata (url):
user_agents = [
"chrome/5.0 (Windows NT 6.0; Win64; x64",
"chrome/5.0 (Windows NT 6.0; Win64; x32",
]
user_agent = random.choice(user_agents)
header_ = {'User-Agent': user_agent}
req = urllib.request.Request(url, headers=header_)
flipkart_html = urllib.request.urlopen(req).read()
f_soup = soup(flipkart_html,'html.parser')
for e in f_soup.select('div[]'):
try:
asin = e.find('a',{'class':'_1fQZEK'})['href'].split('=')[1].split('&')[0]
except:
asin = 'No ASIN Found'
data.append({
'ASIN': asin
})
return f_soup
def getnextpage(f_soup):
try:
page = f_soup.findAll('a',attrs={"class": '_1LKTO3'})[-1]['href']
url = 'https://www.flipkart.com' str(page)
except:
url = None
return url
keywords = ['iphone']
for k in keywords:
url = 'https://www.flipkart.com/search?q=' k
while True:
geturl = getdata(url)
url = getnextpage(geturl)
if not url:
break
print(url)
output
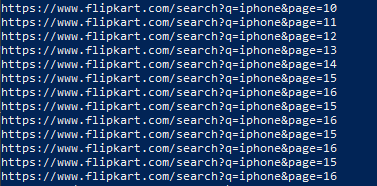
To terminate your loop, check for the existence of the next button; if it's not there then terminate.
CodePudding user response:
Main issue is your selection of the element containing the link to next page:
f_soup.findAll('a',attrs={"class": '_1LKTO3'})[-1]['href']It swaps between
NextandPreviouswhat causes the issue. Please avoid usingfindAll()in newer code and usefind_all()instead.Select your element more specific e.g.
css selectorsand:-soup-contains("Next"):f_soup.select_one('a[href*="&page="]:-soup-contains("Next")')['href']In this case the loop will
breakuntil resting last page.