I want to figure out when before events (e.g. an exam) a platform gets used.
I have a lot of access data from two years
2018-09-02 14:46:56 #earliest log
2020-10-12 23:30:13 #last log
and loads of events within those years I would like to look at. e.g.:
2019-11-26 15:00:00
2019-12-19 15:00:00
2020-01-22 08:30:00
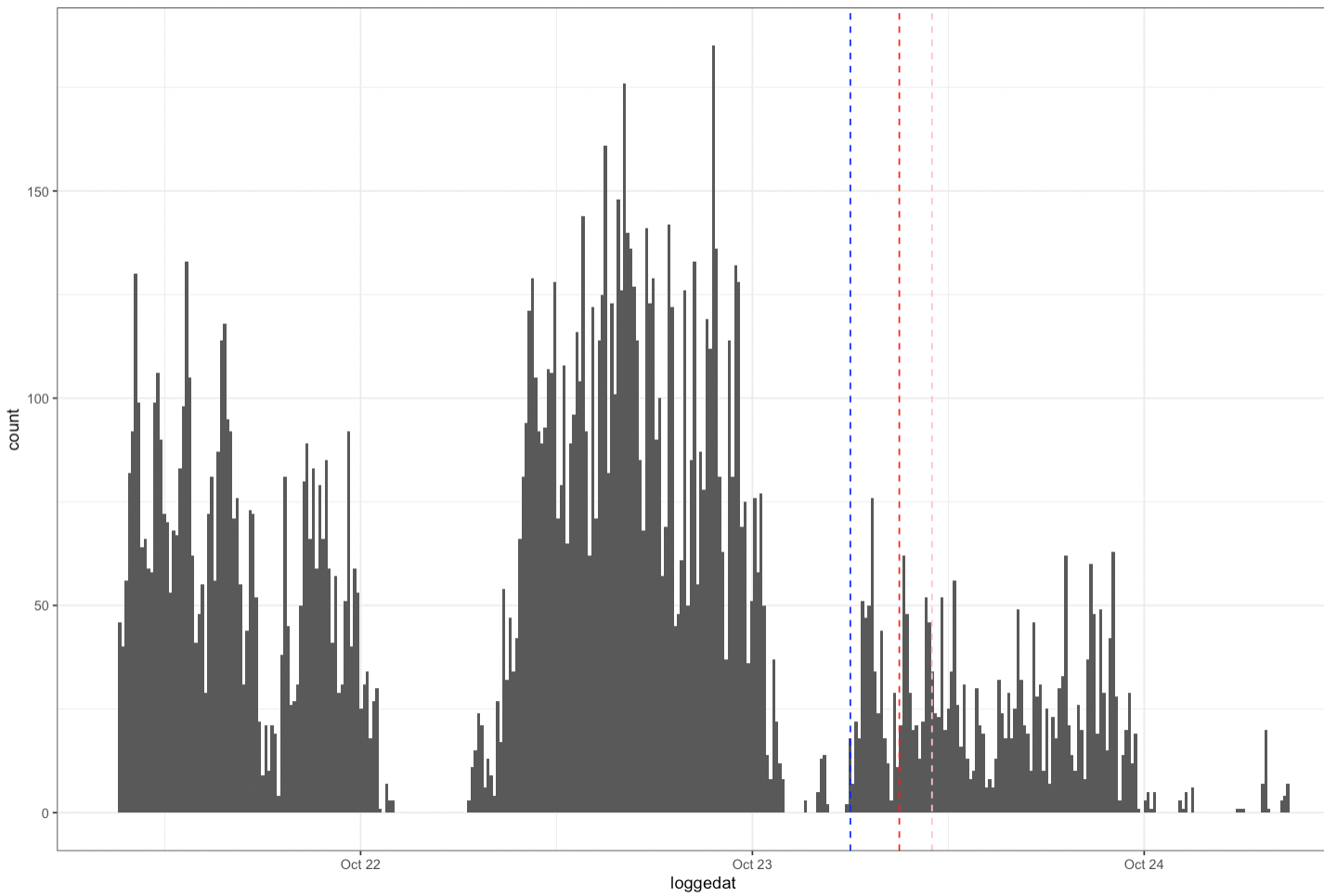
I managed to graph one event (red line) and what happens around it (in this case up to 48h prior).
df %>%
ggplot(aes(x = earliestlog))
geom_histogram(binwidth = 700)
geom_vline(aes(xintercept=as.POSIXct("2019-10-23 09:00:00")),
color="red", linetype="dashed", size=0.5)
xlim(as.POSIXct("2019-10-21 09:00:00"), as.POSIXct("2019-10-24 09:00:00"))
What I now want is to do this for all events and have it overlayed with all events basically being the same red line so I am able to see what happens in the weeks prior. Can be a density plot or whatever really.
Since I am working with date and timestamps I don't know if there is a smart way to do this. I was thinking of manipulating all dates between events (converting everything between events to let's say 1.1.2022-31.1.2022) so that they in the end can be graphed, but that's obviously not a very neat solution and events are not evenly spaced, so I don't think it would work.
Here is my log data in grey and my moments which I want to overlay in red.
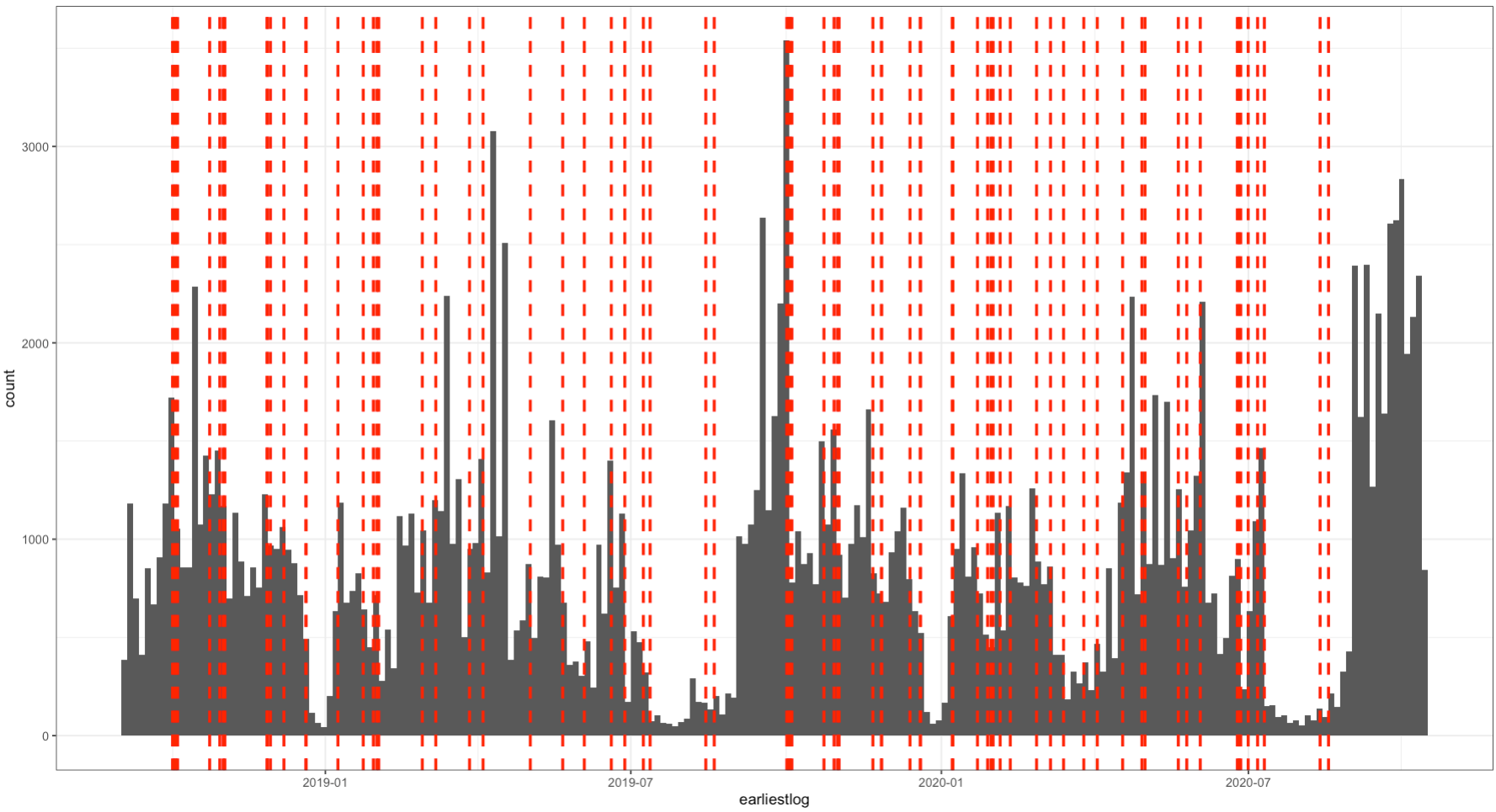
The time should not be manipulated as overlaying a 9am and 12pm event would obviously shift the data from the logs leading up to the 12pm event back by 3 hours.
Any idea if this is doable?
my second df (exam) contains all 77 exam datetimesin the column exam$start.
This is what I think my code needs to do:
select a row from exam$start, select that datetime
select all rows from df where (df$earliestlog >= exam$start-days(31)) & (df$earliestlog <= exam$start) #this should get all logs from the month prior up to the exam date
paste into new df, but adjust dates to dates of past month
and then repeat this until it has done this for all 77 exam moments in exam$start
That should leave me with a dataset that has all the timestamps adjusted to the past month which I can then easily plot as they basically overlay automatically.
Here is a sample of my dataset:
structure(list(session_id = c(19L, 19L, 24L, 25L, 25L, 28L, 28L
), moduleid = c(397L, 902L, 690L, 1698L, 1755L, 1271L, 1280L),
numslidesread = c(1L, 1L, 31L, 31L, 44L, 3L, 6L), totalsecondsspent = c(5L,
13L, 1607L, 1903L, 556L, 34L, 327L), earliestlog = structure(c(1535901815.913,
1535901806.71, 1535908234.25, 1535908317.923, 1535910210.9,
1535917280.053, 1535916929.16), tzone = "", class = c("POSIXct",
"POSIXt"))), row.names = c(NA, -7L), class = c("tbl_df",
"tbl", "data.frame"))
CodePudding user response:
If I'm understanding your latest comments, you want to express the log volume in terms of "time until next exam."
I think this can be done straightforwardly by merging your log data and your exam data to define a new variable showing "time until next exam."
Here's some example data:
set.seed(42)
logs <- data.frame(
status = "log",
timestamps = as.POSIXct("2022-01-01 00:00", tz = "UTC") runif(100, max = 30*24*60*60)
)
exams <- data.frame(
status = "exam",
timestamps = as.POSIXct(c("2022-01-05 12:00", "2022-01-31 14:00"), tz = "UTC")
)
We can then bind those two data sets together (with compatible "timestamps" variables), arrange, and fill in the next exam time so it appears in each row. Then we can plot using that as our time variable.
library(dplyr)
bind_rows(logs, exams) %>%
arrange(timestamps) %>%
mutate(next_exam = if_else(status == "exam", timestamps, NA_POSIXct_)) %>%
tidyr::fill(next_exam, .direction = "up") %>%
mutate(hrs_vs_exam = as.numeric(timestamps - next_exam)/(60*60)) %>%
filter(status == "log") %>%
ggplot(aes(hrs_vs_exam))
geom_histogram(binwidth = 24, boundary = 0)