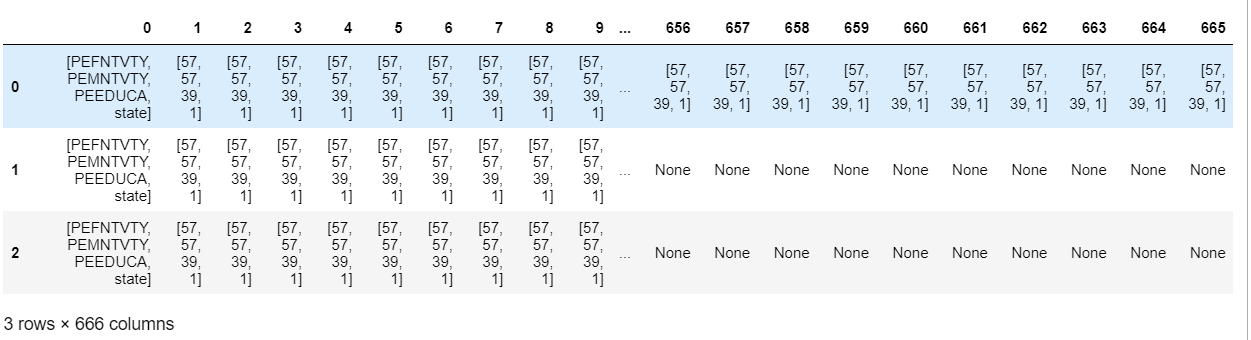
My pandaframe looks very weird after running the code. The data doesnt not come with a year/month variable so I have to add them manually. Is there a way I could do that?
sample = []
url1 = "https://api.census.gov/data/2018/cps/basic/jan?get=PEFNTVTY,PEMNTVTY&for=state:01&PEEDUCA=39&key=YOUR_KEY_GOES_HERE"
url2 = "https://api.census.gov/data/2018/cps/basic/feb?get=PEFNTVTY,PEMNTVTY&for=state:01&PEEDUCA=39&key=YOUR_KEY_GOES_HERE"
url3 = "https://api.census.gov/data/2018/cps/basic/mar?get=PEFNTVTY,PEMNTVTY&for=state:01&PEEDUCA=39&key=YOUR_KEY_GOES_HERE"
sample.append(requests.get(url1).text)
sample.append(requests.get(url2).text)
sample.append(requests.get(url3).text)
sample = [json.loads(i) for i in sample]
sample = pd.DataFrame(sample)
sample
CodePudding user response:
The response to each API call is a JSON array of arrays. You called the wrong DataFrame constructor. Try this:
base_url = "https://api.census.gov/data/2018/cps/basic"
params = {
"get": "PEFNTVTY,PEMNTVTY",
"for": "state:01",
"PEEDUCA": 39,
}
df = []
for month in ["jan", "feb", "mar"]:
r = requests.get(f"{base_url}/{month}", params=params)
r.raise_for_status()
j = r.json()
df.append(pd.DataFrame.from_records(j[1:], columns=j[0]).assign(month=month))
df = pd.concat(df)
Result:
PEFNTVTY PEMNTVTY PEEDUCA state month
0 57 57 39 1 jan
1 57 57 39 1 jan
2 57 57 39 1 jan
3 57 57 39 1 jan
4 57 57 39 1 jan
...
CodePudding user response:
Consider read_json to directly read the Census URL API inside a user-defined method. Then zip to iterate pairwise through years and months to build data frame and assign corresponding columns:
import pandas as pd
import calendar
def get_census_data(year, month):
# BUILD DYNAMIC URL
url = (
f"https://api.census.gov/data/{year}/cps/basic/{month.lower()}?"
"get=PEFNTVTY,PEMNTVTY&for=state:01"
)
# CLEAN RAW DATA FOR APPROPRIATE ROWS AND COLS, ASSIGN YEAR/MONTH COLS
raw_df = pd.read_json(url)
cps_df = (
pd.DataFrame(raw_df.iloc[1:,])
.set_axis(raw_df.iloc[0,], axis="columns", inplace=False)
.assign(year = year, month = month)
)
return cps_df
# MONTH AND YEAR LISTS
months = calendar.month_abbr[1:13]
years = [2018] * len(months)
# ITERATE PAIRWISE THROUGH LISTS
cps_list = [get_census_data(yr, mo) for yr, mo in zip(years, months)]
# COMPILE FINAL DATA FRAME
cps_df = pd.concat(cps_list, ignore_index=True)
Output
cps_df
0 PEFNTVTY PEMNTVTY state year month
0 57 57 1 2018 Jan
1 57 57 1 2018 Jan
2 57 57 1 2018 Jan
3 57 57 1 2018 Jan
4 57 57 1 2018 Jan
... ... ... ... ...
29710 57 57 1 2018 Dec
29711 57 57 1 2018 Dec
29712 57 57 1 2018 Dec
29713 57 57 1 2018 Dec
29714 57 57 1 2018 Dec
[29715 rows x 5 columns]