I have two df frames
df = pd.DataFrame({'1': [0, 0, 0, 0, 0, 0],
'2': [0, 0, 0, 0, 0, 0],
'3': [0, 10, 20, 30, 40, 50]})
df2 = pd.DataFrame({'1': [53, 76, 77, 96, 58, 64],
'2': [42, 61, 65, 74, 45, 54],
'3': [36, 42, 24, 54, 10, 80],})
What I am looking for is a new column in df which states how many times that row has values from df2 in a row which are >= to each number.
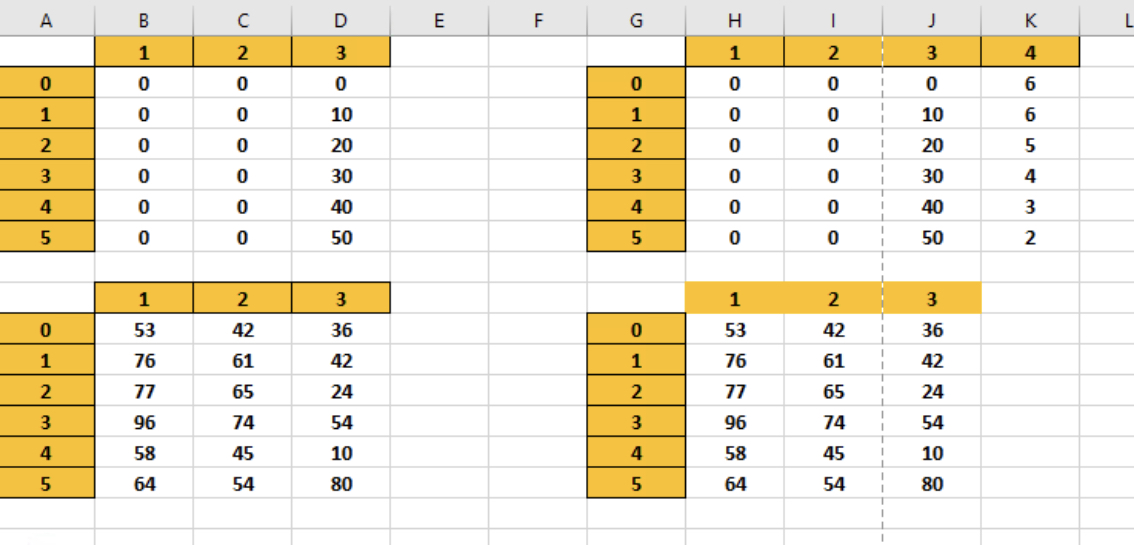
Hope I’ve explained it well enough thanks
CodePudding user response:
Try with apply:
df["count"] = df.apply(lambda row: row.le(df2).all(1).sum(), axis=1)
>>> df
1 2 3 count
0 0 0 0 6
1 0 0 10 6
2 0 0 20 5
3 0 0 30 4
4 0 0 40 3
5 0 0 50 2
CodePudding user response:
Try with outer sub
df['count'] = (np.subtract.outer(df2.to_numpy(),df.to_numpy())>=0).all((1,-1)).sum(0)
df
Out[307]:
1 2 3 count
0 0 0 0 6
1 0 0 10 6
2 0 0 20 5
3 0 0 30 4
4 0 0 40 3
5 0 0 50 2