I have a dataframe in the following schema, that I extract from a Hive table using the SQL below:
| Id | Group_name | Sub_group_number | Year_Month |
|---|---|---|---|
| 1 | Active | 1 | 202110 |
| 2 | Active | 3 | 202110 |
| 3 | Inactive | 4 | 202110 |
| 4 | Active | 1 | 202110 |
The T-SQL to extract the information is:
SELECT Id, Group_Name, Sub_group_number, Year_Month
FROM table
WHERE Year_Month = 202110
AND id IN (SELECT Id FROM table WHERE Year_Month = 202109 AND Sub_group_number = 1)
After extract this information I want to group by Sub_group to extract the Id quantity as below:
df = (df.withColumn('FROM', F.lit(1))
.groupBy('Year_Month', 'FROM', 'Sub_group_number')
.count())
The result is a table as below:
| Year_Month | From | Sub_group_number | Quantity |
|---|---|---|---|
| 202110 | 1 | 1 | 2 |
| 202110 | 1 | 3 | 1 |
| 202110 | 1 | 4 | 1 |
Until this point there is no issue on my code and I'm able to run and execute action commands with Spark. The issue happens when I try to make the year_month and sub_group as parameters of my T-SQL in order to have a complete table. I'm using the following code:
sub_groups = [i for i in range(22)]
year_months = [202101, 202102, 202103]
for month in year_months:
for group in sub_groups:
query = f"""SELECT Id, Group_Name, Sub_group_number, Year_Month
FROM table
WHERE Year_Month = {month 1}
AND id IN (SELECT Id FROM table WHERE Year_Month = {month} AND Sub_group_number = {group})"""
df_temp = (spark.sql(query)
.withColumn('FROM', F.lit(group))
.groupBy('Year_Month', 'FROM', 'Sub_group_number')
.count())
df = df.union(df_temp).dropDuplicates()
When I execute a df.show() or try to write as Table I have the issue:
An error occurred while calling o8522.showString
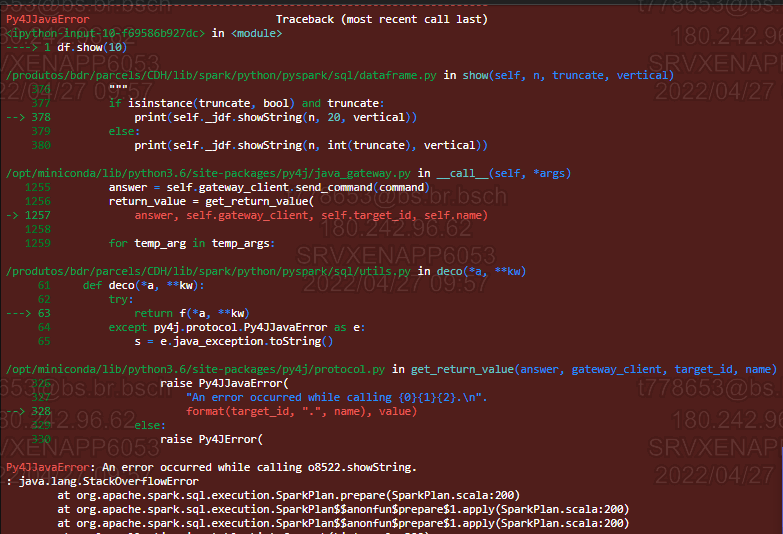
Any ideas of what is causing this error?
CodePudding user response:
You're attempting string interpolation.
If using Python, maybe try this:
query = "SELECT Id, Group_Name, Sub_group_number, Year_Month
FROM table
WHERE Year_Month = {0}
AND id IN (SELECT Id FROM table WHERE Year_Month = {1}
AND Sub_group_number = {2})".format(month 1, month, group)
CodePudding user response:
The error states it is StackOverflowError that can happen when DAG plan grows too much. Because of Spark's lazy evaluation, this could easily happen with for-loops, especially you have nested for-loop.
To solve this, you want to avoid for-loop as much as possible and in your case , it seems you don't need it.
sub_groups = [i for i in range(22)]
year_months = [202101, 202102, 202103]
# Modify this to use datetime lib for more robustness (ex: handle 202112 -> 202201).
month_plus = [x 1 for x in year_months]
def _to_str_elms(li):
return [str(x) for x in li]
spark.sql("""
SELECT Id, Group_Name, Sub_group_number, Year_Month
FROM table
WHERE Year_Month IN ({','.join(_to_str_elms(month_plus))})
AND id IN (SELECT Id FROM table WHERE Year_Month IN ({','.join(_to_str_elms(month))}) AND Sub_group_number IN ({','.join(_to_str_elms(sub_groups))}))
""")