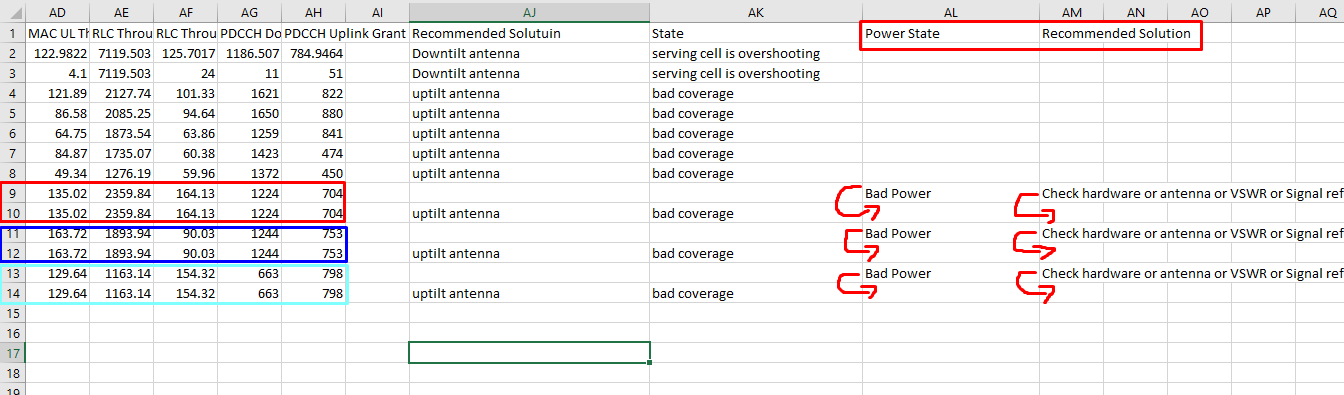
I have this data, and I need to merge the two selected columns with the other row because its duplicated rows cames from my code.
So, how could I do this?
CodePudding user response:
Here is a way to do what your question asks:
df[['State_new', 'Solution_new']] = df[['Power State', 'Recommended Solution']].shift()
mask = ~df['State_new'].isna()
df.loc[mask, 'State'] = df.loc[mask, 'State_new']
df.loc[mask, 'Recommended Solutuin'] = df.loc[mask, 'Solution_new']
df = df.drop(columns=['State_new', 'Solution_new', 'Power State', 'Recommended Solution'])[~df['State'].isna()].reset_index(drop=True)
Explanation:
- create versions of the important data from your code shifted down by one row
- create a boolean mask indicating which of these shifted rows are not empty
- use this mask to overwrite the content of the
StateandRecommended Solutuincolumns (NOTE: using original column labels verbatim from OP's question) with the updated data from your code contained in the shifted columns - drop the columns used to perform the update as they are no longer needed
- use
reset_indexto create a new integer range index without gaps.
In case it's helpful, here is sample code to pull the dataframe in from Excel:
import pandas as pd
df = pd.read_excel('TestBook.xlsx', sheet_name='TestSheet', usecols='AD:AM')
Here's the input dataframe:
MAC RLC RLC 2 PDCCH Down PDCCH Uplink Unnamed: 34 Recommended Solutuin State Power State Recommended Solution
0 122.9822 7119.503 125.7017 1186.507 784.9464 NaN Downtitlt antenna serving cell is overshooting NaN NaN
1 4.1000 7119.503 24.0000 11.000 51.0000 NaN Downtitlt antenna serving cell is overshooting NaN NaN
2 121.8900 2127.740 101.3300 1621.000 822.0000 NaN uptilt antenna bad coverage NaN NaN
3 86.5800 2085.250 94.6400 1650.000 880.0000 NaN uptilt antenna bad coverage NaN NaN
4 64.7500 1873.540 63.8600 1259.000 841.0000 NaN uptilt antenna bad coverage NaN NaN
5 84.8700 1735.070 60.3800 1423.000 474.0000 NaN uptilt antenna bad coverage NaN NaN
6 49.3400 1276.190 59.9600 1372.000 450.0000 NaN uptilt antenna bad coverage NaN NaN
7 135.0200 2359.840 164.1300 1224.000 704.0000 NaN NaN NaN Bad Power Check hardware etc.
8 135.0200 2359.840 164.1300 1224.000 704.0000 NaN uptilt antenna bad coverage NaN NaN
9 163.7200 1893.940 90.0300 1244.000 753.0000 NaN NaN NaN Bad Power Check hardware etc.
10 163.7200 1893.940 90.0300 1244.000 753.0000 NaN uptilt antenna bad coverage NaN NaN
11 129.6400 1163.140 154.3200 663.000 798.0000 NaN NaN NaN Bad Power Check hardware etc.
12 129.6400 1163.140 154.3200 663.000 798.0000 NaN uptilt antenna bad coverage NaN NaN
Here is the sample output:
MAC RLC RLC 2 PDCCH Down PDCCH Uplink Unnamed: 34 Recommended Solutuin State
0 122.9822 7119.503 125.7017 1186.507 784.9464 NaN Downtitlt antenna serving cell is overshooting
1 4.1000 7119.503 24.0000 11.000 51.0000 NaN Downtitlt antenna serving cell is overshooting
2 121.8900 2127.740 101.3300 1621.000 822.0000 NaN uptilt antenna bad coverage
3 86.5800 2085.250 94.6400 1650.000 880.0000 NaN uptilt antenna bad coverage
4 64.7500 1873.540 63.8600 1259.000 841.0000 NaN uptilt antenna bad coverage
5 84.8700 1735.070 60.3800 1423.000 474.0000 NaN uptilt antenna bad coverage
6 49.3400 1276.190 59.9600 1372.000 450.0000 NaN uptilt antenna bad coverage
7 135.0200 2359.840 164.1300 1224.000 704.0000 NaN Check hardware etc. Bad Power
8 163.7200 1893.940 90.0300 1244.000 753.0000 NaN Check hardware etc. Bad Power
9 129.6400 1163.140 154.3200 663.000 798.0000 NaN Check hardware etc. Bad Power
CodePudding user response:
You can use groupby to combine the rows by columns:
df = pd.DataFrame(data)
new_df = df.groupby(['MAC', 'RLC1', 'RLC2', 'POCCH', 'POCCH Up']).sum()
new_df.reset_index()
CodePudding user response:
You can do something like:
fill_cols = ['Power State', 'Recommended Solution 2']
dup_cols = ['MAC_UL','RLC_Through_1','RLC_Through_2','PDCCH Down', 'PDCCH Up']
m = df.duplicated(subset=dup_cols, keep=False)
df_fill = df.loc[m,fill_cols]
df_fill[df_fill['Power State']==''] = np.NaN
df_fill[df_fill['Recommended Solution 2']==''] = np.NaN
df.loc[m,fill_cols]=df_fill.ffill()
- Get duplicated rows using
duplicated - Fill empty values with NaN
- Then use
ffill