I have a dataset I am trying to group by some common values and then sum up some other values. The tricky part is I want to add some sort of weighting that keeps the largest number, I'll try to elaborate more below:
I've created a dummy data frame that is along the lines of my data just for example purposes:
df = pd.DataFrame({'Family': ['Contactors', 'Contactors', 'Contactors'],
'Cell': ['EP&C', 'EXR', 'C&S'],
'Visits': ['25620', '626', '40']})
This produces a table like so:
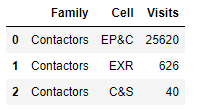
So, in this example I would want all of the 'Contactors' to be grouped up by EP&C (as this has the highest visits to start with) but I would like all of the visits summed up and the other 'Cell' values dropped, so I would be left with something like this:
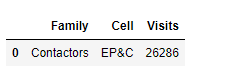
Could anyone advise?
Thanks.
CodePudding user response:
IIUC, you can use:
(df
# convert to numeric
.assign(Visits=pd.to_numeric(df['Visits']))
# ensure the top row per group is the highest visits
.sort_values(by=['Family', 'Visits'], ascending=False)
# for groups per Family
.groupby('Family', sort=False, as_index=False)
# aggregate per group: Cell (first row, i.e top) and Visits (sum of rows)
.agg({'Cell': 'first', 'Visits': sum})
)
output:
Family Cell Visits
0 Contactors EP&C 26286