I have the next DataFrame:
a = [{'order': '789', 'name': 'A', 'date': 20220501, 'sum': 15.1}, {'order': '456', 'name': 'A', 'date': 20220501, 'sum': 19}, {'order': '704', 'name': 'B', 'date': 20220502, 'sum': 14.1}, {'order': '704', 'name': 'B', 'date': 20220502, 'sum': 22.9}, {'order': '700', 'name': 'B', 'date': 20220502, 'sum': 30.1}, {'order': '710', 'name': 'B', 'date': 20220502, 'sum': 10.5}]
df = pd.DataFrame(a)
print(df)
I need, to distinct (count) value in column order and to add values to the new column order_count, grouping by columns name and date, sum values in column sum.
I need to get the next result:
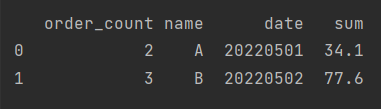
CodePudding user response:
In your case do
out = df.groupby(['name','date'],as_index=False).agg({'sum':'sum','order':'nunique'})
Out[652]:
name date sum order
0 A 20220501 34.1 2
1 B 20220502 77.6 3
CodePudding user response:
import pandas as pd
df[['name','date','sum']].groupby(by=['name','date']).sum().reset_index().rename(columns={'sum':'order_count'}).join(df[['name','date','sum']].groupby(by=['name','date']).count().reset_index().drop(['name','date'],axis=1))