I have a data frame like:
df= pd.DataFrame({'A': [1,2,3,4,5], 'B': ['a b c', 'a cf', 'bdf','az c', 'ab f']})
List of lists to be matched:
lsts = [['a','c'], ['b', 'd']]
I need to get all the rows from df where column 'B' contains all the elements from any of the sub-lists. It should contain either both ('a' and 'b') or contain both ('b' and 'd').
So, the output should look like
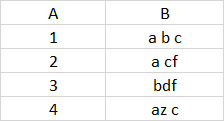
What will be an optimal way to do this? Thanks.
CodePudding user response:
You can use .str.findall to convert characters in column B to lists then loop the lsts to use set.issubset to check if lst is subset of lists in column B. At last use np.logical_or to reduce the boolean list.
import numpy as np
lsts = [['a','c'], ['b', 'd']]
bs = df['B'].str.findall(r'\w').apply(set)
m = np.logical_or.reduce([bs.apply(set(lst).issubset) for lst in lsts])
print(df[m])
A B
0 1 a b c
1 2 a cf
2 3 bdf
3 4 az c
CodePudding user response:
You can use set operations:
lsts = [['a','c'], ['b', 'd']]
sets = [set(l) for l in lsts]
df[[any(S.issubset(x) for S in sets) for x in df['B']]]
Output:
A B
0 1 a b c
1 2 a cf
2 3 bdf
3 4 az c