Suppose I have two dataframes (note column indices):
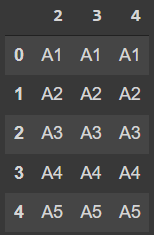 = A =
= A =
2 3 4
0 A1 A1 A1
1 A2 A2 A2
2 A3 A3 A3
3 A4 A4 A4
4 A5 A5 A5
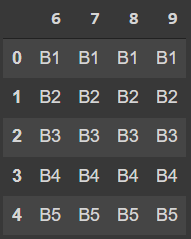 = B =
= B =
6 7 8 9
0 B1 B1 B1 B1
1 B2 B2 B2 B2
2 B3 B3 B3 B3
3 B4 B4 B4 B4
4 B5 B5 B5 B5
I want to merge them into dataframe, where they will be at their index places, and the rest filled with nothing, for example:
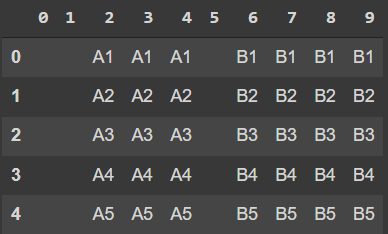
What is the best (pythonic) way to do it?
Those dataframes were generated with the following code:
import pandas as pd
df = pd.DataFrame(columns = range(10))
A = ['A' str(i) for i in range(1, 6)]
B = ['B' str(i) for i in range(1, 6)]
df[[2,3,4]] = list(zip(A, A, A))
df[[6,7,8,9]] = list(zip(B, B, B, B))
df.fillna('', inplace = True) # Output dataframe
df.drop(columns = [0, 1] list(range(5, 10))) # A dataframe
df.drop(columns = list(range(0, 6))) # B dataframe
UPD I thank all contributors, that was very insightful. reindex seems to be the most elegant way to do it. However, constantstranger in the end provided the most thoughtful update, and also showed convenient way to store smaller DataFrame inside non-empty large dataframe, according to its columns indexes, which is also valuable for me. So, however difficult it was to choose best answer, I pick his.
For whoever will struggle with the similar task, I might add, that fill_value = '' during reindex will help to get rid of pesky NaNs.
CodePudding user response:
Let us do reindex after join
C = A.join(B)
C = C.reindex(range(C.columns.max() 1), axis=1)
0 1 2 3 4 5 6 7 8 9
0 NaN NaN A1 A1 A1 NaN B1 B1 B1 B1
1 NaN NaN A2 A2 A2 NaN B2 B2 B2 B2
2 NaN NaN A3 A3 A3 NaN B3 B3 B3 B3
3 NaN NaN A4 A4 A4 NaN B4 B4 B4 B4
4 NaN NaN A5 A5 A5 NaN B5 B5 B5 B5
CodePudding user response:
Here is a way to do what you've asked:
import pandas as pd
import numpy as np
A = pd.DataFrame(data={j: ['A' str(i) for i in range(1, 6)] for j in range(2, 5)})
B = pd.DataFrame(data={j: ['B' str(i) for i in range(1, 6)] for j in range(6, 10)})
print(A)
print(B)
newColumns = range(1 max(A.columns[-1], B.columns[-1]))
df = pd.DataFrame({newCol: [np.nan] * max(len(A.index), len(B.index)) for newCol in newColumns})
df[A.columns] = A
df[B.columns] = B
print(df)
Output:
2 3 4
0 A1 A1 A1
1 A2 A2 A2
2 A3 A3 A3
3 A4 A4 A4
4 A5 A5 A5
6 7 8 9
0 B1 B1 B1 B1
1 B2 B2 B2 B2
2 B3 B3 B3 B3
3 B4 B4 B4 B4
4 B5 B5 B5 B5
0 1 2 3 4 5 6 7 8 9
0 NaN NaN A1 A1 A1 NaN B1 B1 B1 B1
1 NaN NaN A2 A2 A2 NaN B2 B2 B2 B2
2 NaN NaN A3 A3 A3 NaN B3 B3 B3 B3
3 NaN NaN A4 A4 A4 NaN B4 B4 B4 B4
4 NaN NaN A5 A5 A5 NaN B5 B5 B5 B5
If you prefer a fill value other than NaN (such as the empty string), you can change this in the initialization of df.
UPDATE:
An alternative to the = A and = B lines above is this:
df[list(A.columns) list(B.columns)] = pd.concat([A, B], axis=1)
UPDATE #2:
Ohter answers (by @mozway and @Shubham Sharma) have suggested using reindex(), which is elegant. I would just note that to be more generic, reindex should probably use the max column label of A and B (rather than relying on one being the larger):
df = pd.concat([A, B], axis = 1).reindex(range(max(A.columns[-1], B.columns[-1]) 1), axis = 'columns')
CodePudding user response:
You can concat and reindex:
out = pd.concat([A, B], axis=1).reindex(columns=range(B.columns.max() 1))
or, if you don't know in which input lies the max columns (python ≥ 3.8):
out = (d:=pd.concat([A, B], axis=1)).reindex(columns=range(d.columns.max() 1))
output:
0 1 2 3 4 5 6 7 8 9
0 NaN NaN A1 A1 A1 NaN B1 B1 B1 B1
1 NaN NaN A2 A2 A2 NaN B2 B2 B2 B2
2 NaN NaN A3 A3 A3 NaN B3 B3 B3 B3
3 NaN NaN A4 A4 A4 NaN B4 B4 B4 B4
4 NaN NaN A5 A5 A5 NaN B5 B5 B5 B5