I have a large dataframe broken into the following columns: "country", "year", "week", "conflict_event_count". The data records the country, year, and week in which a conflict event occurred; however, I'd also like to create rows for the weeks in which a conflict event didn't take place and assign a "0" to that week's event count. I.e., make implicit missing country-weeks explicit. This is how my dataframe currently looks:
Country <- c('Afghanistan', 'Afghanistan', 'Afghanistan', 'Algeria', 'Algeria')
Year <- c(1989, 1995, 2019, 1989, 1992)
Week <- c(24, 46, 52, 2, 12)
Conflict_Event_Count <- c(4, 3, 1, 3, 2)
df <- data.frame(Country, Year, Week, Conflict_Event_Count)
df
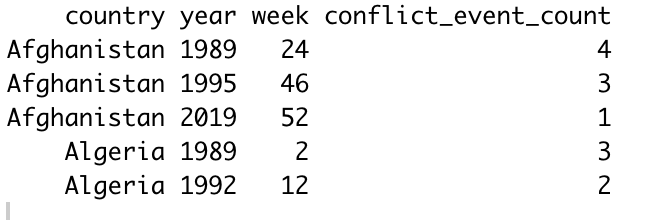
I'm trying to get the 'year' column to cycle through 1989:2019, and for the week column to cycle through 1:53 for each of the 53 weeks in a year. For example, instead of there being a gap between the third and fourth rows in the above dataframe, it would look something more like this:
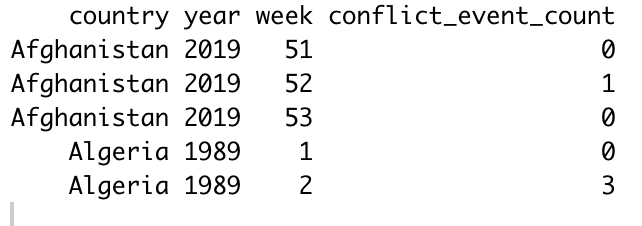
where the existing event counts remain, but the conflict event counts for the missing country-weeks receive a "0".
I tried to start with the 'week' column and used the complete function to fill in the missing week values
df %>% complete(week = seq(min(week), max(week), by = 'week'))
but got an error message because the 'country' column is non-numeric. Does anyone have any ideas about how to generate this sequence? Thanks in advance!
CodePudding user response:
The Country adds an additional layer of complexity. If you are not going to do this separately for each country then you will need to rep the country by a value that is the product of the year span and 53. And the Year-Week id's would need to be rep-ped by number of unique Country values. (I'm not sure this is the correct way to proced. This may be an X-Y problem: do X to get Y when there might be a more efficient Z method to get to Y. You have not told us what the analysis is going to be.)
For one country: I would create a text (character) field (column) that has the year in YYYY format, a delimiter, and append a week (using the caps in your code block rather than the spelling in pictures):
new_col <- paste( rep( min(df$Year):max(df$Year), each=53), "_", 1:53)
df$curr_wks <- paste(df$Year, "_", df$Week)
expand_df <- merge(df, new_col, all=TRUE)
is.na(expand_df$confict_event_count) <- 0
CodePudding user response:
library(tidyverse)
df %>%
group_by(Country) %>%
complete(Year = 1989:2019, Week = 1:52,
fill = list(Conflict_Event_Count = 0))
# A tibble: 3,224 x 4
# Groups: Country [2]
Country Year Week Conflict_Event_Count
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1989 1 0
2 Afghanistan 1989 2 0
3 Afghanistan 1989 3 0
4 Afghanistan 1989 4 0
5 Afghanistan 1989 5 0
6 Afghanistan 1989 6 0
7 Afghanistan 1989 7 0
8 Afghanistan 1989 8 0
9 Afghanistan 1989 9 0
10 Afghanistan 1989 10 0
CodePudding user response:
In base R, consider expand.grid for all possible combinations of the three columns. Then, left join merge your original data:
all_country_year_week <- expand.grid(
Country = unique(original_df$Country),
Year = 1989:2019,
Week = 1:53
)
conflict_events_df <- merge(
all_country_year_week,
original_df,
by = c("Country", "Year", "Week")
all.x = TRUE
) |> transform(
Conflict_Event_Count = ifelse(
is.na(Conflict_Event_Count), 0, Conflict_Event_Count
)
)
CodePudding user response:
If you want to use baseR and seq you could use seq()
df$YWd<-paste(df$Year,df$Week,1,sep="-")
df$date<-as.Date(df$YW,format="%Y-%U-%u") # or other definition of "yearweek"
timeframe<-seq(min(df$date),max(df$date),by="week")
padding<-data.frame(list(date=timeframe)) # create full timeseries
# add Countries
expand.grid(Country=unique(df$Country), date=timeframe)
# merge df’s
padded_df<-merge(
padding,
df[order(df$date),c("date","Country","Conflict_Event_Count")],
all=T )
# Na to 0
is.na(padded_df$confict_event_count) <- 0
The benefit of this approach is that you have a column of class(Date) which is usefull for timeseries stuff (Arima, decomposition,...)