The following code works, but it seems highly inefficient. Is there a more straight forward way to calculate a daily enrollment by site from an entry and exit date.
Data:
df <- data.frame(
id <- seq_along(1:10),
entry_date <- seq(as.Date("2022-01-01"), as.Date("2022-01-10"), by = 1),
exit_date <- seq(as.Date("2022-05-20"), as.Date("2022-05-30"), by = 1),
site <- rep(c("Loc1", "Loc2"), times= 5)
) %>%
set_names("id", "entry_date", "exit_date", "site") %>%
mutate(exit_date = as.character(exit_date))
df[8:10, 3] <- rep("NA", times = 3)
Create a ytd sequence:
date <- seq(as.Date("2022-01-01"), today(), by = 1)
And iterate the function below over it with:
enrolled_ytd <- map_dfr(date, ~ daily_enrollment_fun(.), .id = "date")
Function:
daily_enrollment_fun <- function(date){
df %>%
select(id, entry_date, exit_date, site) %>%
drop_na(site) %>%
mutate(enrolled_int = interval((entry_date), (exit_date))) %>%
distinct(id, .keep_all = T) %>%
mutate(enrolled = date %within% enrolled_int)
}
The output is a dataframe with a TRUE/FALSE enrollment for every id and every day in the sequence of dates. To clean the data, I run the function:
daily_enrollment_clean_fun <- function(date, origin = "2022-01-01") {
enrolled_ytd %>%
mutate(date = as.numeric(date) -1,
date = as.Date(date, origin = origin)) %>%
group_by(date, site, enrolled) %>%
count() %>%
filter(enrolled == "TRUE") %>%
ungroup() %>%
select(-enrolled) %>%
arrange(desc(date))
}
CodePudding user response:
Does this give you what you're looking for? I expect this should be more performant since the calculation here is vectorized once we get the stream of entries and exits into a longer form.
library(tidyverse)
df %>%
pivot_longer(entry_date:exit_date) %>%
filter(!is.na(value)) %>%
mutate(change = if_else(name == "entry_date", 1, -1)) %>%
group_by(site) %>%
arrange(site, value) %>%
mutate(enrollment = cumsum(change)) %>%
complete(value = seq.Date(min(value, na.rm = TRUE),
max(value, na.rm = TRUE),
by = "day")) %>%
fill(enrollment) %>%
ungroup()
Result into ggplot with %>% ggplot(aes(value, enrollment, color = site)) geom_point()
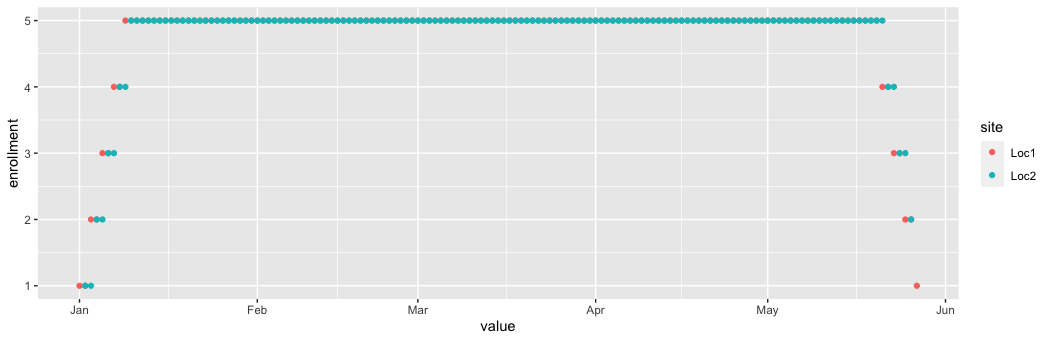
Modified input (to keep both date columns as dates)
library(tidyverse)
df <- data.frame(
id <- seq_along(1:10),
entry_date <- seq(as.Date("2022-01-01"), as.Date("2022-01-10"), by = 1),
exit_date <- seq(as.Date("2022-05-21"), as.Date("2022-05-30"), by = 1),
site <- rep(c("Loc1", "Loc2"), times= 5)
) %>%
set_names("id", "entry_date", "exit_date", "site")
df[8:10, 3] <- rep(NA_real_, times = 3)
CodePudding user response:
Here is an efficient approach using data.table
- setDT()
- update missing exit_date to be equal to the final date in
date - join on the combination (
CJ) of id and date values, by id - set enrollment equal to the sum of rows where
datefalls within the entry and exit date, by date and site
library(data.table)
setDT(df)[is.na(exit_date), exit_date:=max(date)][CJ(date,id=df$id), on=.(id)][
, .(enrollment= sum(date>=entry_date & date<=exit_date)), by=.(date,site)]
Output:
date site enrollment
1: 2022-01-01 Loc1 1
2: 2022-01-01 Loc2 0
3: 2022-01-02 Loc1 1
4: 2022-01-02 Loc2 1
5: 2022-01-03 Loc1 2
---
286: 2022-05-23 Loc2 4
287: 2022-05-24 Loc1 3
288: 2022-05-24 Loc2 4
289: 2022-05-25 Loc1 3
290: 2022-05-25 Loc2 3
Input Data:
library(lubridate)
df <- data.frame(
id <- seq_along(1:10),
entry_date <- seq(as.Date("2022-01-01"), as.Date("2022-01-10"), by = 1),
exit_date <- seq(as.Date("2022-05-21"), as.Date("2022-05-30"), by = 1),
site <- rep(c("Loc1", "Loc2"), times= 5)
) %>%
set_names("id", "entry_date", "exit_date", "site") %>%
mutate(exit_date = as.character(exit_date))
df[8:10, 3] <- rep("NA", times = 3)
date <- seq(as.Date("2022-01-01"), lubridate::today(), by = 1