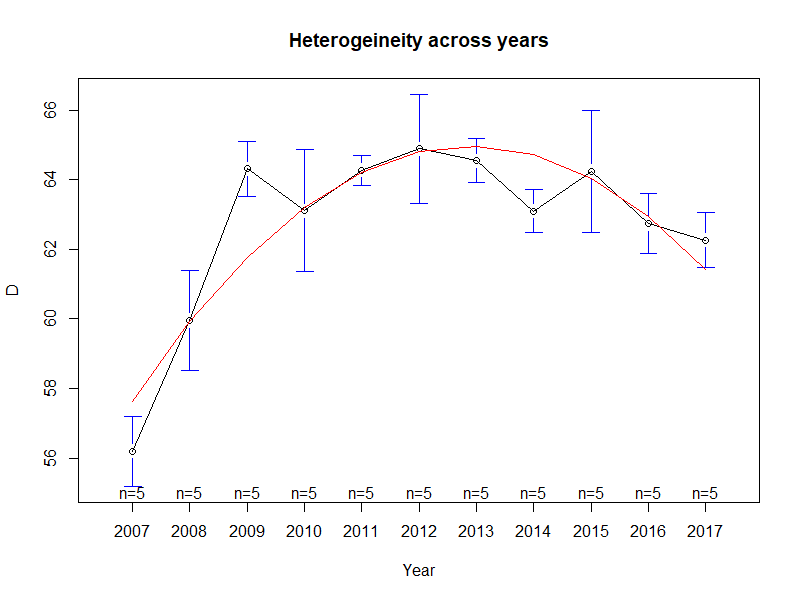
We are analyzing fixed effects heterogeneity across years of a panel database ("mydata") containing values of an economic explained value depending on 12 independent variables. Data correspond to the period 2007-2017 and 142 countries. We use function plotmeans from package gplots being the script as follows:
plotmeans(D ~ Year, main="Heterogeineity across years", data=mydata)
We obtain the graph hereunder:
Is there any function/script on R that can fit the obtained plot into a quadratic curve providing its equation coefficients?
CodePudding user response:
First, fit a quadratic curve:
df <- data.frame(year = c(1,2,3,4,5,6,7,8,9),
D = c(35,26,19,6,1,3,5,12,17))
fit<-lm(D~poly(year,2,raw=TRUE), df)
> summary(fit)
Call:
lm(formula = D ~ poly(year, 2, raw = TRUE), data = df)
Residuals:
Min 1Q Median 3Q Max
-2.987 -1.872 -0.039 1.545 4.305
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 52.786 3.400 15.53 4.5e-06 ***
poly(year, 2, raw = TRUE)1 -17.103 1.561 -10.96 3.4e-05 ***
poly(year, 2, raw = TRUE)2 1.469 0.152 9.65 7.1e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.67 on 6 degrees of freedom
Multiple R-squared: 0.959, Adjusted R-squared: 0.946
F-statistic: 71.1 on 2 and 6 DF, p-value: 6.65e-05
Next count the value of year estimation:
quadratic = fit$coefficient[3]*df$year^2 fit$coefficient[2]*df$year fit$coefficient[1]
At last fit a quadratic curve:
plot(df$year,df$D, main="Heterogeineity across years",
xlab="Year ", ylab="D")
par(new = TRUE)
lines(df$year,quadratic, col="red")
Output:
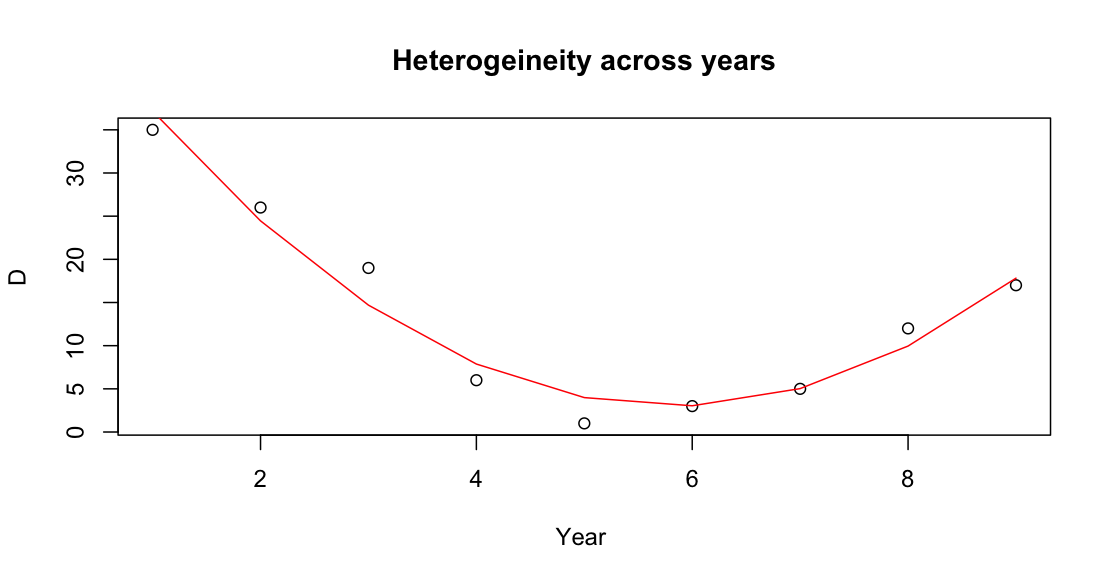
Please note: We don't have your data.
CodePudding user response:
A quadratic fit is quite straightforward in R using the linear model lm function with a quadratic term. The I() function (as is) is necessary to inhibit symbolic interpretation of the "^" operator and simplification the quadratic term. summary (or coef) print the coefficients and predict can be used to plot the curve:
## an example data set with 5 replicates
set.seed(123)
mydata <- data.frame(
Year = rep(2007:2017, each=5),
D = rep(c(56, 60, 64, 63, 65, 65, 64, 63, 64, 63, 62), each=5) rnorm(55)
)
## fit a quadratic model
m <- lm(D ~ Year I(Year^2), data = mydata)
summary(m)
coef(m)
plot(D ~ Year, data = mydata)
lines(mydata$Year, predict(m))
To do the same with plotmeans it is necessary to adjust the x scale.
library(gplots)
plotmeans(D ~ Year, main="Heterogeineity across years", data=mydata)
## plotmeans chances the x axis scale, so we
## need to subtract 2006, so that year 2007 is the first in plotmeans
lines(mydata$Year - 2007 1, predict(m), col="red")