The post looks long but it's really not, its because I am bad at explaining things :)
I am trying to make a NN which classifies O and X letters. Each letter is 6x6 pixels(36 inputs), I max pooled the letters to 2x2 pixels(4 inputs) using Convolutional layer. In my NN architecture I had only 1 output Node, if the output is close to 0 then the letter is "O", if it is closer to 1 then the letter is "X".
- First NN Architecture:
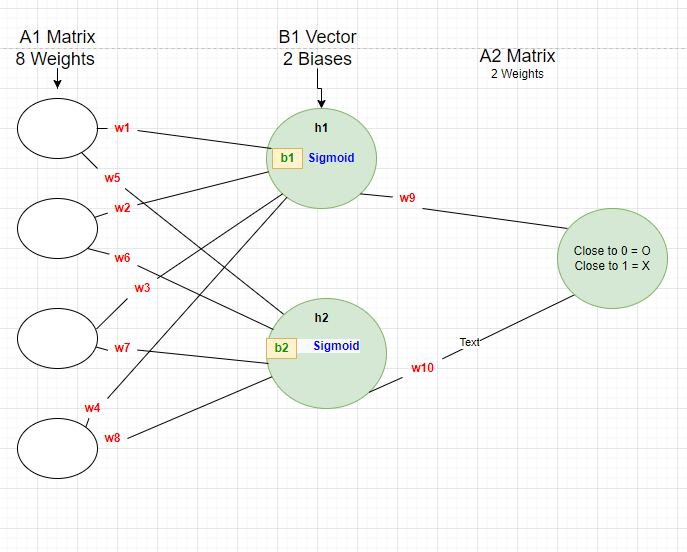
My training data for the first NN Architecture:
x= [[0.46931818, 0.44129729, 0.54988949, 0.54295118], #O Letter Max Pooled from 6x6 to 2x2
[0.54976771, 0.54295118, 0.50129169, 0.54988949]] #X Letter Max Pooled from 6x6 to 2x2
y=[[0],[1]]
As you see above, the label for O letter is zero and the label for X letter is 1. So if the output is closer to 0 then it classifies the input as O Letter, if it is closer to 1 then it classifies the input as X Letter.
This was working fine for me, but when I decided to change my architecture to 2 outputs I started having problems, so I read about Softmax and I think I am implementing it wrong. Here is a photo of my new NN:
- Second NN Architecture
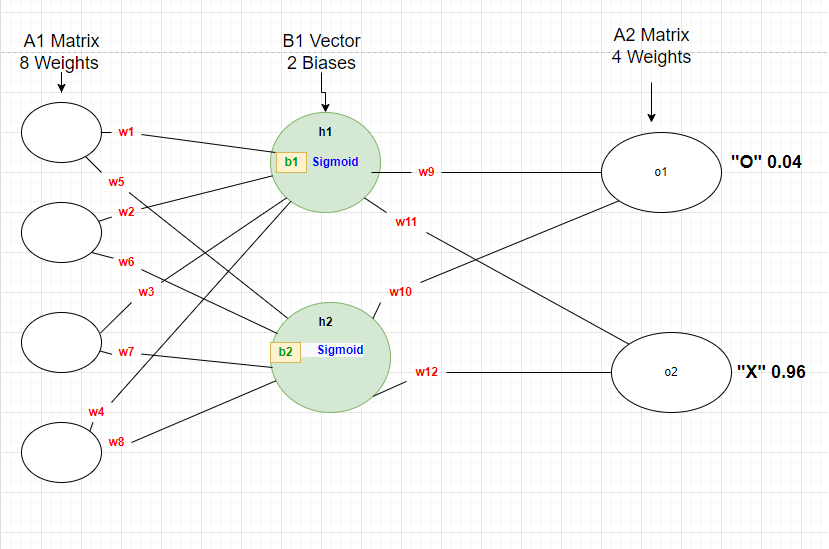
Here are my questions:
1. Should I change my y variable which is y=[[0],[1]] because I
think my new architecture is not classifying it as if its close to 0
or 1 since each letter has its own output node.
2. How will my code know that the o1 node is for O letter and the
o2 node is for X Letter
3. Am I implementing the yPred right in my code while feedforwarding?
In the first architecture I had my y_pred like this: y_pred = o1
because I had only 1 output node. Should I send the o1 and o2 as a
victor to the softmax function and get the highest value? (I really
think I am approaching this wrong) here is the code I wrote:
sum_o1 = (self.w9 * h1 self.w10 * h2)
o1 = sigmoid(sum_o1)
sum_o2 = (self.w11 * h1 self.w12 * h2)
o2 = sigmoid(sum_o2)
#Check this later, might be implemented wrong ######################
y_pred = softmax([o1, o2])
y_pred = max(y_pred)
The reason I think I implemented it wrong because my loss rate sometimes gets higher and sometimes it doesnt change even after 40000 epochs! Here is how I check my loss:
if epoch % 1000 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
- In the first NN architecture, I used to calculate the partial
derivate like this:
d_L_d_ypred = -2 * (y_true - y_pred), how should I calculate it with me new architecture? because now I don't think my y_true will be 0 and 1 anymore. Because I already have 2 nodes (o1 and o2) and each stands for a letter.
I know that I have some misunderstandings because I am a beginner, but I hope someone can explain this to me.
Even tho I have no hope of someone answering this(Since this is how stackoverflow works sometimes and it annoys me), but helps are really really appreciated!! Thanks in advance!
NOTE: Adding the code to make my question about the shapes problem more clear:
class OurNeuralNetwork:
def __init__(self):
# Weights for h1 (First Node in the Hidden Layer)
self.w1 = np.random.normal()
self.w2 = np.random.normal()
self.w3 = np.random.normal()
self.w4 = np.random.normal()
# Weights for h2 (Second Node in the Hidden Layer)
self.w5 = np.random.normal()
self.w6 = np.random.normal()
self.w7 = np.random.normal()
self.w8 = np.random.normal()
# Biases in the hidden layer
self.b1 = np.random.normal() #First Node
self.b2 = np.random.normal() #Second Node
self.w9 = np.random.normal()
self.w10 = np.random.normal()
self.w11 = np.random.normal()
self.w12 = np.random.normal()
def testForward(self, x):
h1 = sigmoid(self.w1 * x[0] self.w2 * x[1] self.w3 * x[2] self.w4 * x[3] self.b1)
h2 = sigmoid(self.w5 * x[0] self.w6 * x[1] self.w7 * x[2] self.w8 * x[3] self.b2)
o1 = sigmoid(self.w9 * h1 self.w10 * h2)
o2 = sigmoid(self.w11 * h1 self.w12 * h2)
output = softmax([o1, o2])
return output
def feedforward(self, x):
h1 = sigmoid(self.w1 * x[0] self.w2 * x[1] self.w3 * x[2] self.w4 * x[3] self.b1)
h2 = sigmoid(self.w5 * x[0] self.w6 * x[1] self.w7 * x[2] self.w8 * x[3] self.b2)
o1 = sigmoid(self.w9 * h1 self.w10 * h2)
o2 = sigmoid(self.w11 * h1 self.w12 * h2)
output = softmax([o1, o2])
return output
def train(self, data, all_y_trues):
learn_rate = 0.01
epochs = 20000
for epoch in range(epochs):
for x, y_true in zip(data, all_y_trues):
#Feedforward
sum_h1 = self.w1 * x[0] self.w2 * x[1] self.w3 * x[2] self.w4 * x[3] self.b1
h1 = sigmoid(sum_h1)
sum_h2 = self.w5 * x[0] self.w6 * x[1] self.w7 * x[2] self.w8 * x[3] self.b2
h2 = sigmoid(sum_h2)
sum_o1 = (self.w9 * h1 self.w10 * h2)
o1 = sigmoid(sum_o1)
sum_o2 = (self.w11 * h1 self.w12 * h2)
o2 = sigmoid(sum_o2)
#Check this later, might be implemented wrong ######################
y_pred = softmax([o1, o2])
## Partial Derivates ->
d_L_d_ypred = -2 * (y_true - y_pred)
# Node o1
d_ypred_d_w9 = h1 * deriv_sigmoid(sum_o1)
d_ypred_d_w10 = h2 * deriv_sigmoid(sum_o1)
#Node o2
d_ypred_d_w11 = h1 * deriv_sigmoid(sum_o2)
d_ypred_d_w12 = h2 * deriv_sigmoid(sum_o2)
d_ypred_d_h1_o1 = self.w9 * deriv_sigmoid(sum_o1)
d_ypred_d_h2_o1 = self.w10 * deriv_sigmoid(sum_o1)
d_ypred_d_h1_o2 = self.w11 * deriv_sigmoid(sum_o2)
d_ypred_d_h2_o2 = self.w12 * deriv_sigmoid(sum_o2)
# Node h1
d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)
d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)
d_h1_d_w3 = x[2] * deriv_sigmoid(sum_h1)
d_h1_d_w4 = x[3] * deriv_sigmoid(sum_h1)
d_h1_d_b1 = deriv_sigmoid(sum_h1)
# Node h2
d_h2_d_w5 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w6 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_w7 = x[2] * deriv_sigmoid(sum_h2)
d_h2_d_w8 = x[3] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# Update weights and biases
# Node h1
self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1_o1 * d_h1_d_w1
self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1_o1 * d_h1_d_w2
self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h1_o1 * d_h1_d_w3
self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h1_o1 * d_h1_d_w4
self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1_o1 * d_h1_d_b1
# Node h2
self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_h2_o2 * d_h2_d_w5
self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_h2_o2 * d_h2_d_w6
self.w7 -= learn_rate * d_L_d_ypred * d_ypred_d_h2_o2 * d_h2_d_w7
self.w8 -= learn_rate * d_L_d_ypred * d_ypred_d_h2_o2 * d_h2_d_w8
self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2_o2 * d_h2_d_b2
# Node o1
self.w9 -= learn_rate * d_L_d_ypred * d_ypred_d_w9
self.w10 -= learn_rate * d_L_d_ypred * d_ypred_d_w10
#Node o2
self.w11 -= learn_rate * d_L_d_ypred * d_ypred_d_w11
self.w12 -= learn_rate * d_L_d_ypred * d_ypred_d_w12
#Check this later after fixing the softmax issue #################################
if epoch % 10000 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
CodePudding user response:
1. Should I change my y variable which is y=[[0],1] because I think my new architecture is not classifying it as if its close to 0 or 1 since each letter has its own output node.
Ans you should change from y=[[0],[1]] to one-hot vector likes y=[[1,0],[0,1]]. It mean that we want the output at index 0 (your first output node) are 1 if the input image is 0. And the output at index 1 (your second output node) are 1 if the input image is x.
2. How will my code know that the o1 node is for O letter and the o2 node is for X Letter
Ans Your model will learn from the onehot label y=[[1,0],[0,1]]. During model training, your model will realize that if it want to minimize the loss function, when the input image is 0, it should fire value 1 from the first output node, and vice versa.
3. Am I implementing the yPred right in my code while feedforwarding? In the first architecture I had my y_pred like this: y_pred = o1 because I had only 1 output node. Should I send the o1 and o2 as a victor to the softmax function and get the highest value? (I really think I am approaching this wrong) here is the code I wrote:
Ans During training, we do need only the probability of class 0 and x to do the back-propagation for updating weight. So, y_pred = max(y_pred) is not needed.
4. In the first NN architecture, I used to calculate the partial derivate like this: d_L_d_ypred = -2 * (y_true - y_pred), how should I calculate it with me new architecture? because now I don't think my y_true will be 0 and 1 anymore. Because I already have 2 nodes (o1 and o2) and each stands for a letter.
Ans maybe this thread can help you