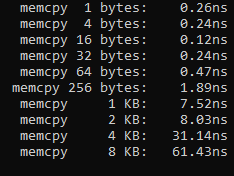
I'm doing some performance measurements. When looking at memcpy, I found a curious effect with small byte sizes. In particular, the fastest byte count to use for my system is 16 bytes. Both smaller and larger sizes get slower. Here's a screenshot of my results from a larger test program.
I've minimized a complete program to reproduce the effect just for 1 and 16 bytes (note this is MSVC code to suppress inlining to prevent optimizer to nuke everything):
#include <chrono>
#include <iostream>
using dbl_ns = std::chrono::duration<double, std::nano>;
template<size_t n>
struct memcopy_perf {
uint8_t m_source[n]{};
uint8_t m_target[n]{};
__declspec(noinline) auto f() -> void
{
constexpr int repeats = 50'000;
const auto t0 = std::chrono::high_resolution_clock::now();
for (int i = 0; i < repeats; i)
std::memcpy(m_target, m_source, n);
const auto t1 = std::chrono::high_resolution_clock::now();
std::cout << "time per memcpy: " << dbl_ns(t1 - t0).count()/repeats << " ns\n";
}
};
int main()
{
memcopy_perf<1>{}.f();
memcopy_perf<16>{}.f();
return 0;
}
I would have hand-waved away a minimum at 8 bytes (maybe because of 16 bit on a 64 bit register size) or at 64 bytes (cache line size). But I'm somewhat puzzled at the 16 bytes. The effect is reproducible on my system and not a fluke.
Notes: I'm aware of the intricacies of performance measurements. Yes, this is in release mode. Yes, I made sure things are not optimized away. Yes, I'm aware there are libraries for this. Yes, n is too low, etc etc. This is a minimal example. I checked the asm, it calls memcpy.
CodePudding user response:
I assume that MSVC 19 is used since there is not information about the MSVC version yet.
The benchmark is biased so it cannot actually help to tell which one is faster, especially for such a small timing.
Indeed, here is the assembly code of MSVC 19 with /O2 between the two calls to std::chrono::high_resolution_clock::now:
mov cl, BYTE PTR [esi]
add esp, 4
mov eax, 50000 ; 0000c350H
npad 6
$LL4@f:
sub eax, 1 <--- This is what you measure !
jne SHORT $LL4@f
lea eax, DWORD PTR _t1$[esp 20]
mov BYTE PTR [esi 1], cl
push eax
One can see that you measure a nearly empty loop that is completely useless and more than half the instructions are not the ones meant to be measured. The only useful instructions are certainly:
mov cl, BYTE PTR [esi]
mov BYTE PTR [esi 1], cl
Even assuming that the compiler could generate such a code, the call to std::chrono::high_resolution_clock::now certainly takes several dozens of nano seconds (since the usual solution to measure very small timing precisely is to use RDTSC and RDTSCP). This is far more than the time to execute such instruction. In fact, at such a granularity the notion of wall clock time vanishes. Instructions are typically executed in parallel in an out of order way and are also pipelined. At this scale one need to consider the latency of each instruction, their reciprocal throughput, their dependencies, etc.
An alternative solution is to reimplement the benchmark so the compiler cannot optimize this. But this is pretty hard to do since copying 1 byte is nearly free on modern x86 architectures (compared to the overhead of the related instructions needed to compute the addresses, loop, etc.).
AFAIK copying 1 byte on an AMD Zen2 processor has a reciprocal throughput of ~1 cycle (1 load 1 store scheduled on both 2 load ports and 2 store ports) assuming data is in the L1 cache. The latency to read/write a value in the L1 cache is 4-5 cycles so the latency of the copy may be 8-10 cycles. For more information about this architecture please check this.
CodePudding user response:
Best way to know is to check the resulting assembly. for example if 16 byte version is aligned on 16 then it uses aligned load/store operations and becomes faster than 4 byte / 1 byte version.
Maybe if it can not vectorize(use register) due to bad alignment, it falls back to do cache copy like mov operations on memory address instead of register.