Looking for pointers optimizing my JOIN GROUP BY.
I have a primary table, StorageItemEntities with an index on (PrefabName, WorldScanId).
My secondary table ZDOEntities has a primary key on its Id field.
Both tables have ~2M rows.
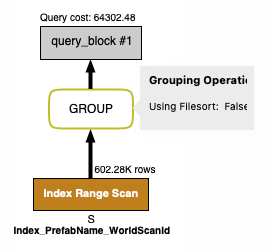
Base query runs @ 200ms:
SELECT S.WorldScanId, COUNT(1)
FROM StorageItemEntities S
WHERE S.PrefabName = "Wood"
GROUP BY S.WorldScanId
-> Group aggregate: count(1) (cost=147224.83 rows=602280) (actual time=15.268..209.465 rows=15 loops=1)
-> Filter: (S.PrefabName = 'Wood') (cost=86996.83 rows=602280) (actual time=1.019..188.031 rows=308003 loops=1)
-> Covering index range scan on S using Index_PrefabName_WorldScanId over (PrefabName = 'Wood') (cost=86996.83 rows=602280) (actual time=1.017..132.640 rows=308003 loops=1)
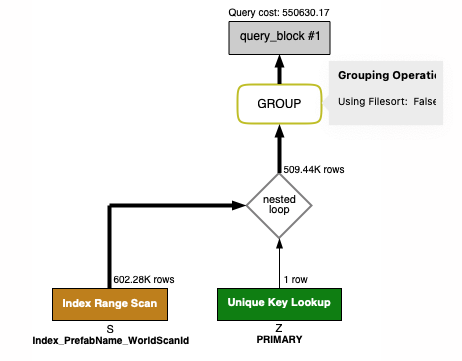
When adding the join, it jumps to 2000ms
SELECT S.WorldScanId, COUNT(1)
FROM StorageItemEntities S
JOIN ZDOEntities Z ON Z.Id = S.StorageContainerZdoId
WHERE S.PrefabName = "Wood"
GROUP BY S.WorldScanId
-> Group aggregate: count(1) (cost=639196.62 rows=602280) (actual time=199.596..2209.068 rows=14 loops=1)
-> Nested loop inner join (cost=578968.62 rows=602280) (actual time=1.143..2185.803 rows=286957 loops=1)
-> Index range scan on S using Index_PrefabName_WorldScanId over (PrefabName = 'Wood'), with index condition: (S.PrefabName = 'Wood') (cost=86978.19 rows=602280) (actual time=1.122..1340.627 rows=308003 loops=1)
-> Single-row covering index lookup on Z using PRIMARY (Id=S.StorageContainerZdoId) (cost=0.85 rows=1) (actual time=0.003..0.003 rows=1 loops=308003)
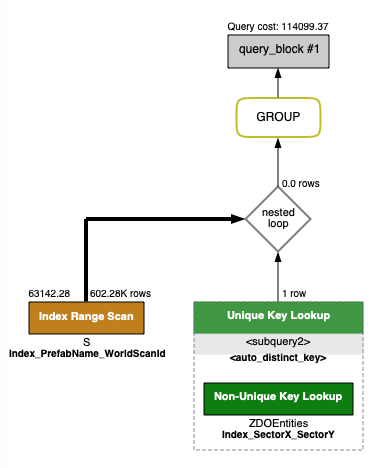
I've also tried separating it out to a subquery, which yielded worse performance
SELECT S.WorldScanId, COUNT(1)
FROM StorageItemEntities S
WHERE S.PrefabName = "Wood"
AND EXISTS (Select 1 FROM ZDOEntities Z WHERE Z.Id = S.StorageContainerZdoId)
GROUP BY S.WorldScanId
As well as a CTE
WITH Z AS (
SELECT Id FROM ZDOEntities
WHERE (SectorX, SectorY) IN ((-1, 1))
)
SELECT S.WorldScanId, COUNT(1)
FROM StorageItemEntities S
WHERE S.PrefabName = "Wood"
AND S.StorageContainerZdoId NOT IN (SELECT * FROM Z)
GROUP BY S.WorldScanId
I'd like to better understand why this has such a heavy impact and how to approach this.
CodePudding user response:
The plans show you why there is a performance hit. The original query can be computed by doing a single range scan on an index with a bit of grouping - there’s quite a lot of matching rows so it takes a couple hundred milliseconds to complete. When you add the join it has to now check every matching row to see if it can complete the join condition too, this adds one index range scan per matching row in your original table - of course that’s going to take a lot more time.
You can potentially improve the performance by limiting the number of rows being joined - you could place an additional group by operation so that it is only done per unique combination of WorldScanId, StorageContainerZdoId.
Something like:
SELECT SQ.WorldScanId, SUM(cnt) cnt
FROM (
SELECT S.WorldScanId, S. StorageContainerZdoId, COUNT(1) cnt
FROM StorageItemEntities S
WHERE S.PrefabName = "Wood"
GROUP BY S.WorldScanId, S. StorageContainerZdoId
) SQ
JOIN ZDOEntities Z ON Z.Id = SQ.StorageContainerZdoId
GROUP BY SQ.WorldScanId
Performance might also be improved by utilising a hash join - this would enable you to just read from both tables separately the once and combine those results. It might be faster depending on the size of ZDOEntities and how the StorageContainerZdoId column is distributed. Upgrading to at least MySQL 8 would allow hash joins to be used, where hopefully the optimizer can make the right decision.
CodePudding user response:
Add this "composite" index:
INDEX(PrefabName, WorldScanId)
with the columns in that order. If you currently have INDEX(PrefabName), it is probably beneficial to DROP it.
For further discussion, please provide SHOW CREATE TABLE for any table(s) involved.
As for "why does the JOIN take so much longer" -- simply because of so many "unique key lookups". And the lack of having the key in the index being scanned.
Your second query (with the JOIN) will either inflate the count (due to 1:many explosion) or decrease the count (by filtering out items that don't have a matching row in the second table). That inflation or deflation may be desired, or may lead to the "wrong" answer, while taking extra time.
If you like the results, then one of these indexes would help because of being "covering":
INDEX(PrefabName, WorldScanId, StorageContainerZdoId)
INDEX(PrefabName, StorageContainerZdoId, WorldScanId)
(I don't know which would be better.)
Since "query cost" is a crude estimate, it may not relate accurately to the actual time that the query takes. What were the actual timings for the 3 variants? And did you get the same results?
If you find that CTEs or Windowing variants run much slower, then I give this lame excuse: CTEs were recently added to keep up with other products. Optimization of any new feature usually comes a few years after the implementation.