The objective is to assign 1s to any index in the group that is a higher value than the one retrieved from idxmax()
import numpy as np
import pandas as pd
df = pd.DataFrame({'id':[1, 1, 1, 2, 2, 2, 3, 3, 3], 'val':[1,np.NaN, 0, np.NaN, 1, 0, 1, 0, 0]})
id val
0 1 1.0
1 1 NaN
2 1 0.0
3 2 NaN
4 2 1.0
5 2 0.0
6 3 1.0
7 3 0.0
8 3 0.0
We can use idxmax() to get the index values for the highest value in each group
test = df.groupby('id')['val'].idxmax()
id
1 0
2 4
3 6
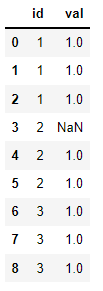
The objective is to transform the data to look as such (which is that every value in group that has a higher index than the one from idxmax() gets assigned a 1.
id val
0 1 1.0
1 1 1.0
2 1 1.0
3 2 NaN
4 2 1.0
5 2 1.0
6 3 1.0
7 3 1.0
8 3 1.0
This question does not necessarily need to be done with idxmax(). Open to any suggestions.
CodePudding user response:
If i understand correctly the problem, you can use apply and np.where
nd = df.groupby('id')['val'].idxmax().tolist()
df['val'] = df.groupby('id')['val'].transform(lambda x: np.where(x.index>nd[x.name-1], 1, x))
df
Output:
id val
0 1 1.0
1 1 1.0
2 1 1.0
3 2 NaN
4 2 1.0
5 2 1.0
6 3 1.0
7 3 1.0
8 3 1.0
CodePudding user response:
Try
df = pd.DataFrame({'id':[1, 1, 1, 2, 2, 2, 3, 3, 3], 'val':[1,np.NaN, 0, np.NaN, 1, 0, 1, 0, 0]})
# cummax fills everything after the first True to True in each group
# mask replaces the 0s that were originally nan by nan
df.val = df.val.eq(1).groupby(df.id).cummax().astype(int).mask(lambda x: x.eq(0) & df.val.isna())
df