I have created a dataframe called df with this code:
# initialize list of lists
data = {'ID': [1,2,3,4,5,6,7],
'feature1': [100,32,100,100,100,93,100],
'feature2': [100,32,100,100,100,93,100],
'feature3': [100,32,100,100,100,93,100],
}
# Create DataFrame
df = pd.DataFrame(data)
The dataframe looks like this:
print(df)
ID feature1 feature2 feature3
0 1 100 100 100
1 2 32 32 32
2 3 100 100 100
3 4 100 100 100
4 5 100 100 100
5 6 93 93 93
6 7 100 100 100
I want to remove the rows in which the values of columns:
feature1andfeature2andfeature3are exactly the same as the previous row. In the example above, I need to remove rows3and4, so that the resulting dataframe will look like this:
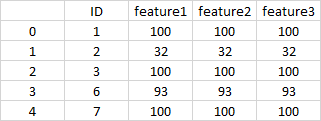
CodePudding user response:
Filter the feature like columns then calculate difference between previous and current row and check whether the difference is 0 for all the feature columns
df[~df.filter(like='feature').diff().eq(0).all(1)]
ID feature1 feature2 feature3
0 1 100 100 100
1 2 32 32 32
2 3 100 100 100
5 6 93 93 93
6 7 100 100 100