I have a list of excel files that follow the below structure (toy):
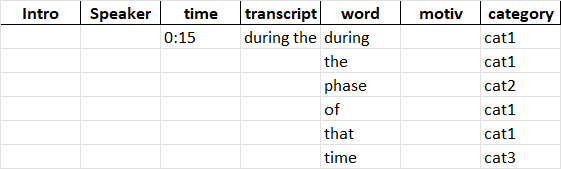
data1 = [["","","0:15","during the phase of that time","during","","cat1"],["","","","","the","","cat1"],["","","","","phase","","cat2"],["","","","","of","","cat1"],["","","","","that","","cat1"],["","","","","time","","cat3"]]
data2 = [["1","1","0:19","at what point is enough enough tommy","at","","cat1"],["","","","","what","","cat2"],["","","","","point","","cat2"],["","","","","is","","cat2"],["","","","","enough","","cat1"],["","","","","enough","","cat1"],["","","","","tommy","","cat3"]]
df1 = pd.DataFrame(data1, columns=['Intro', 'Speaker','time','transcript','word','motiv','category'])
df2 = pd.DataFrame(data2, columns=['Intro', 'Speaker','time','transcript','word','motiv','category'])
df_list = [df1,df2]
names = ["file1","file2"]
for i in range(len(df_list)):
filename = 'Filename' names[i] '.xlsx'
writer = ExcelWriter(filename)
print(filename)
df_list[i].to_excel(writer, 'Sheet1', index=False)
writer.save()
My goal with this list (over 200 df's) is to get summary data of specific columns and store that information into another aggregated excel document. In this toy dataset, the summary example would include a count of how many times cat1, cat2, and cat3 appeared in the "category" column.
My final output in an excel file called "results.xlsx" would look something like this:

I have a very limited knowledge of pandas, and my code so far has been a frankenstein of other projects I've worked on that worked with lists of dataframes. So far, I have:
#Get directory of excel files (using df_list for toy dataset)
os.chdir("path")
path = os.getcwd()
csv_files = glob.glob(os.path.join(path, "*.xlsx"))
#Set aside list
li = []
#Create aggregate dataframe
frame = pd.DataFrame()
for f in csv_files:
# read the csv file
df = pd.read_excel(f).clean_names()
#Set filename variable
frame['filename'] = os.path.basename(f)
#Set category 1 counts variable
frame['category1'] = df.iloc[:,6].value_counts()
#Append aggregated results to aggregate dataframe
li.append(frame)
#Concatenate results
frame2 = pd.concat(li)
However, the results I'm getting do not at all match what I am expecting when I apply it to my actual data. Specifically, I am getting an index with the actual variable I am counting (category 1), only the very last excel file in the list of files is provided in the result, and my category 1 variable is empty:
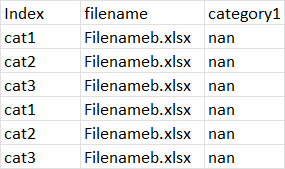 This repeats continuously for the length of number of files in my list.
This repeats continuously for the length of number of files in my list.
I have no clue what I am doing wrong here, any tips that could steer me in the right direction?
CodePudding user response:
Here is one approach:
from pathlib import Path
files = Path('.').glob('*.xlsx')
pd.DataFrame(pd.read_excel(f)['category'].value_counts().rename(f.stem) for f in files)
cat1 cat2 cat3
Filenamefile1 4 1 1
Filenamefile2 3 3 1
...