Hi I have a sql query that results in the output like this
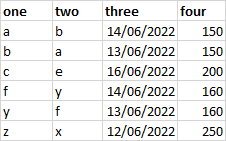
I want the output to look something like this:

Requirement:
- row should not have duplicate when CONCATENATE(column one column two) or CONCATENATE(column two column one)
- the duplicate value that is lower in column three is dropped
CodePudding user response:
You can join the table with itself to find related pairs. Then discarding the unneeded ones becomes easier:
select x.*
from t x
left join t y on y.one = x.two and x.one = y.two
where y.one is null or x.one < y.one
EDIT:
If the values are coming from a query already you can reuse place it as a subquery of this one. For example
with t as (
-- your long query here
)
select x.*
from t x
left join t y on y.one = x.two and x.one = y.two
where y.one is null or x.one < y.one
CodePudding user response:
If window functions are available you can do this:
with cte1 as (
select least(one, two) as one, greatest(one, two) as two, three, four
from t
), cte2 as (
select cte1.*, row_number() over (partition by one, two order by three desc) as rn
from cte1
)
select *
from cte2
where rn = 1
It is possible to achieve the same result without window functions but the query would be complicated, something like:
select *
from t
where (least(one, two), greatest(one, two), three) in (
select least(one, two), greatest(one, two), max(three)
from t
group by 1, 2
)