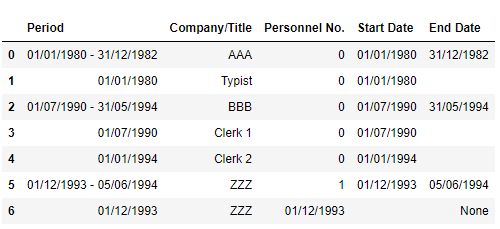
I have the following current dataframe and desired dataframe shown below. I have tried a few method but was unable to get my desired output.
data = [['Period', 'Company/Title', 'Personnel No.', 'Start Date', 'End Date'],
['01/01/1980 - 31/12/1982', 'AAA', '0', '01/01/1980', '31/12/1982'],
['01/01/1980', 'Typist', '0', '01/01/1980', ''],
['01/07/1990 - 31/05/1994', 'BBB', '0', '01/07/1990', '31/05/1994'],
['01/07/1990', 'Clerk 1', '0', '01/07/1990', ''],
['01/01/1994', 'Clerk 2', '0', '01/01/1994', ''],
['01/12/1993 - 05/06/1994', 'ZZZ', '1', '01/12/1993', '05/06/1994'],
['01/12/1993', 'ZZZ', '1', '01/12/1993', '']]
data_df = pd.DataFrame(data[1:], columns = [data[0]])
data_df
desire_output = [['Period', 'Company/Title', 'Personnel No.', 'Start Date', 'End Date'],
['01/01/1980 - 31/12/1982', 'AAA', '0', '01/01/1980', '31/12/1982'],
['01/01/1980', 'AAA - Typist', '0', '01/01/1980', '31/12/1982'],
['01/07/1990 - 31/05/1994', 'BBB', '0', '01/07/1990', '31/05/1994'],
['01/07/1990', 'BBB - Clerk 1', '0', '01/07/1990', '31/12/1993'],
['01/01/1994', 'BBB - Clerk 2', '0', '01/01/1994', '31/05/1994'],
['01/12/1993 - 05/06/1994', 'ZZZ', '1', '01/12/1993', '05/06/1994'],
['01/12/1993', 'ZZZ - Executive', '1', '01/12/1993', '05/06/1994']]
desire_output_df = pd.DataFrame(desire_output[1:], columns = [desire_output[0]])
desire_output_df
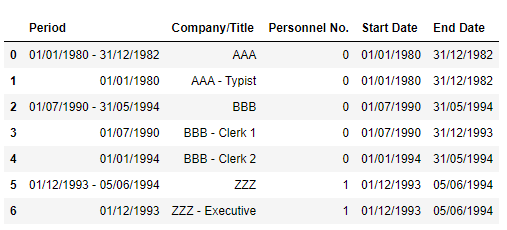
- Can imagine the data is from linkedin in where the first row contains the total period a person is with a organisation. Next 2 rows should the breakdown of each row within the same organisation.
- Row with title will get company name from row with period that contains dash "-"
- For personnel no. with multiple role within the same company, the end date would be the previous row date - day.
I did a indx, row in data that check if "-" in row['Period'] and get the company name and manage to store the company name with the role (e.g. "AAA- Typist" but unable to solve the rest. Appreciate any advice on how can i do this.
Thank you!
CodePudding user response:
I would like to suggest you to migrate your data into a proper database.
Anyway, here is a working code. The key idea for end date process is using shift instead of loop. Typo-like values in the original question are changed.
The code is quite ugly and there may be better method to solve your question.
1. Load data
import pandas as pd
from datetime import timedelta
data = [['Period', 'Company/Title', 'Personal No.', 'Start Date', 'End Date'],
['01/01/1980 - 31/12/1982', 'AAA', '0', '01/01/1980', '31/12/1982'],
['01/01/1980', 'Typist', '0', '01/01/1980', ''],
['01/07/1990 - 31/05/1994', 'BBB', '0', '01/07/1990', '31/05/1994'],
['01/07/1990', 'Clerk 1', '0', '01/07/1990', ''],
['01/01/1994', 'Clerk 2', '0', '01/01/1994', ''],
['01/12/1993 - 05/06/1994', 'ZZZ', '1', '01/12/1993', '05/06/1994'],
['01/12/1993', 'Executive', '1', '01/12/1993', '']]
df = pd.DataFrame(data[1:], columns = [data[0]])
Result
Period Company/Title Personal No. Start Date End Date
0 01/01/1980 - 31/12/1982 AAA 0 01/01/1980 31/12/1982
1 01/01/1980 Typist 0 01/01/1980
2 01/07/1990 - 31/05/1994 BBB 0 01/07/1990 31/05/1994
3 01/07/1990 Clerk 1 0 01/07/1990
4 01/01/1994 Clerk 2 0 01/01/1994
5 01/12/1993 - 05/06/1994 ZZZ 1 01/12/1993 05/06/1994
6 01/12/1993 Executive 1 01/12/1993
2. Process for Company/Title
df['Company'] = df['Company/Title'].loc[df.apply(lambda row: '-' in row['Period'], axis=1)]
df['Company'] = df['Company'].fillna(method='ffill')
df['Title'] = df['Company/Title'].loc[df.apply(lambda row: '-' not in row['Period'], axis=1)]
df['Company/Title'] = df.apply(lambda row: row['Company'] if pd.isna(row['Title']) else row['Company'] ' - ' row['Title'], axis=1)
Result
Period Company/Title Personal No. Start Date \
0 01/01/1980 - 31/12/1982 AAA 0 01/01/1980
1 01/01/1980 AAA - Typist 0 01/01/1980
2 01/07/1990 - 31/05/1994 BBB 0 01/07/1990
3 01/07/1990 BBB - Clerk 1 0 01/07/1990
4 01/01/1994 BBB - Clerk 2 0 01/01/1994
5 01/12/1993 - 05/06/1994 ZZZ 1 01/12/1993
6 01/12/1993 ZZZ - Executive 1 01/12/1993
End Date Company Title
0 31/12/1982 AAA NaN
1 AAA Typist
2 31/05/1994 BBB NaN
3 BBB Clerk 1
4 BBB Clerk 2
5 05/06/1994 ZZZ NaN
6 ZZZ Executive
3. Process for End Date
df['End Date'] = df['End Date'].replace('', method='ffill')
df['Start Date Offset Next'] = (pd.to_datetime(df['Start Date'].squeeze(), format='%d/%m/%Y') - timedelta(days=1)).shift(-1).squeeze().dt.strftime('%d/%m/%Y')
df['Personal No. Next'] = df['Personal No.'].shift(-1)
df['Company Next'] = df['Company'].shift(-1)
df['Title Next'] = df['Title'].shift(-1)
idx_change_end_date = df.apply(lambda row: (row['Personal No.'] == row['Personal No. Next']) & (row['Company'] == row['Company Next']) & (row['Title'] != row['Title Next']) & pd.notna(row['Title']) & pd.notna(row['Title Next']), axis=1)
df.loc[idx_change_end_date, 'End Date'] = df.loc[idx_change_end_date, 'Start Date Offset Next'].squeeze()
df = df.drop(['Company', 'Title', 'Start Date Offset Next', 'Personal No. Next', 'Company Next', 'Title Next'], level=0, axis=1)
Result
Period Company/Title Personal No. Start Date \
0 01/01/1980 - 31/12/1982 AAA 0 01/01/1980
1 01/01/1980 AAA - Typist 0 01/01/1980
2 01/07/1990 - 31/05/1994 BBB 0 01/07/1990
3 01/07/1990 BBB - Clerk 1 0 01/07/1990
4 01/01/1994 BBB - Clerk 2 0 01/01/1994
5 01/12/1993 - 05/06/1994 ZZZ 1 01/12/1993
6 01/12/1993 ZZZ - Executive 1 01/12/1993
End Date
0 31/12/1982
1 31/12/1982
2 31/05/1994
3 31/12/1993
4 31/05/1994
5 05/06/1994
6 05/06/1994