So I am working on testing financial performance of some stocks. I have a pandas column "signal" that by certain logic has "buy" or "sell" signals.
Now these signals occur at random intervals, but whenever they do, almost always they are repeated in a number of consecutive rows.
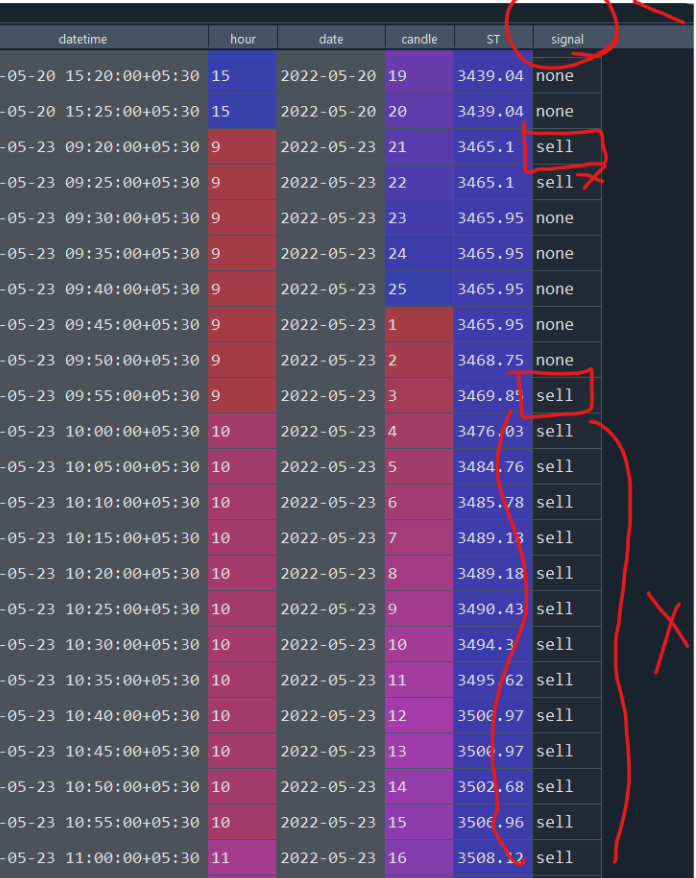
I would like to only keep the 1st instance every time this happens, and remove the consecutive instances of the "buy" / "sell" word. Something like shown below -

CodePudding user response:
Where the signal is equal to sell and the previous value row's signal is sell, then assign none.
df.loc[df['signal'].eq('sell') & df['signal'].eq(df['signal'].shift()), 'signal'] = 'none'
CodePudding user response:
data = {'Signal': ['sell', 'buy', 'sell', 'sell', 'sell', 'none', 'none', 'none', 'sell', 'sell'], 'candle': [20, 21, 19, 18, 1, 2, 3,4, 5,6]}
# Create DataFrame
df = pd.DataFrame(data)
Remove duplicates:
df.loc[((df["Signal"].shift(-1) != df['Signal']) | (df["Signal"] == "none"))]
Or
df.loc[df["Signal"].ne(df["Signal"].shift()) | (df["Signal"].eq("none"))]
CodePudding user response:
You can use : to change the sell and buy at the same time
df.loc[df['signal'].eq(df['signal'].shift()), 'signal'] = 'none'