I have a dataframe 'merged_df' that looks like this:
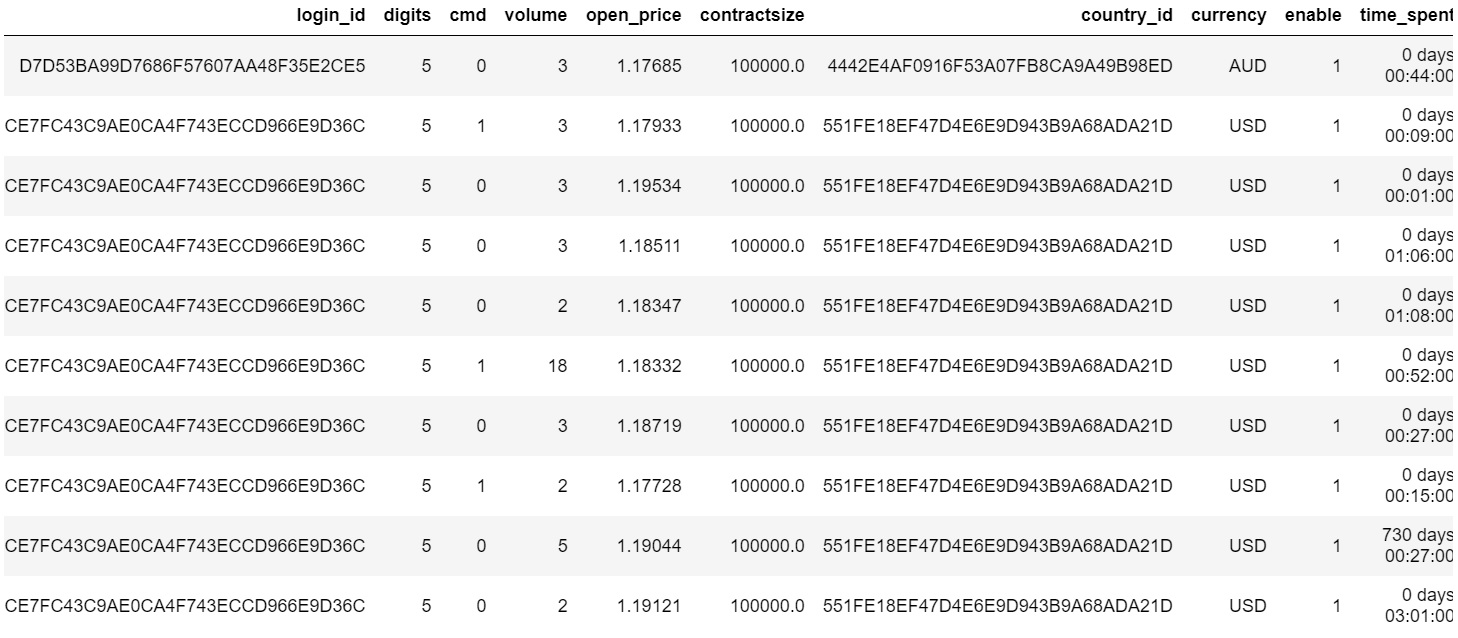
I am interested in the columns, 'login_id' & 'volume', but there are many duplicate entries in the 'login_id' column. I want to make another dataframe with unique 'login_id' and the sum of 'volume' for each unique 'login_id'.
CodePudding user response:
Will this get you what you want?
df = pd.DataFrame({
'login_id' : [1, 1, 2, 2, 3],
'Volumn' : [10, 10, 20, 20, 50]
})
df_new = df.groupby('login_id', as_index = False)['Volumn'].sum().sort_values('Volumn', ascending = False)