I have a dataframe which results from:
df_grouped = df.groupby(['A', 'B'])['A'].count().sort_values(ascending=False)
df_grouped = pd.DataFrame(df_grouped)
new_index = pd.MultiIndex.from_tuples(df_grouped.index)
df_grouped.index = new_index
df_grouped.reset_index(inplace=True)
df_grouped.columns = ['A', 'B', 'count']
Then, df_grouped is something like:
| A | B | count |
|---|---|---|
| A_1 | B_1 | 10 |
| A_1 | B_2 | 51 |
| A_1 | B_3 | 25 |
| A_1 | B_4 | 12 |
| A_1 | B_5 | 2 |
| A_2 | B_1 | 19 |
| A_2 | B_3 | 5 |
| A_3 | B_5 | 18 |
| A_3 | B_4 | 33 |
| A_3 | B_5 | 44 |
| A_4 | B_1 | 29 |
| A_5 | B_2 | 32 |
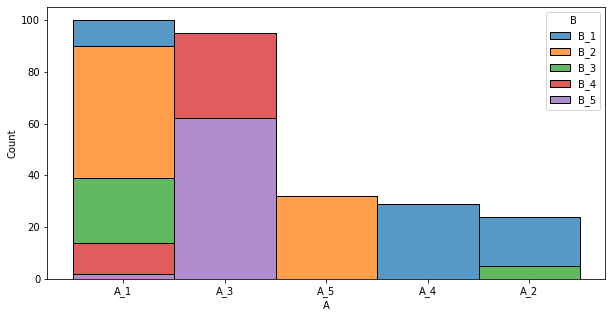
I have plotted a seaborn.histplot using the following code:
fig, ax = plt.subplots(1, 1, figsize=(10,5))
sns.histplot(x='A', hue='B', data=df_grouped, ax=ax, multiple='stack', weights='count')
and results in the following image:
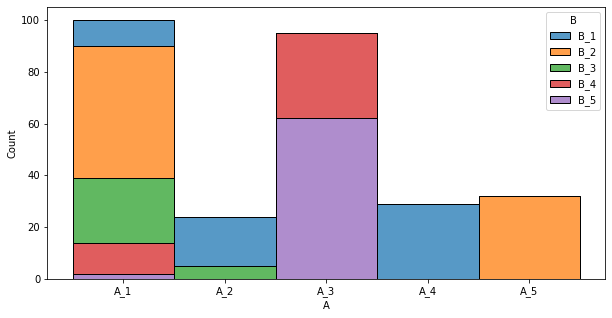
What I would like is to order the plot based on the total counts of each value of A. I have tried different methods, but I am not able to get a successful result.
Edit
I found a way to do what I wanted.
What I did, is to calculate the total counts by df['A'] values:
df['total_count'] = df.groupby(by='A')['count'].transform('sum')
df = df.sort_values(by=['total_count'], ascending=False)
Then, by using the same plot code from above, I got the desired result.
The answer is similar to what Redox proposed.
In any case, I will try the other options proposed.
CodePudding user response:
- To be clear, the visualization is a stacked bar chart, it's not a histogram, as a histrogram represents the distribution of continuous values, while this is the counts of discrete categorical values.
- This answer starts with the raw dataframe, not the dataframe created with
.groupby.
- The easiest way to do this is create a frequency table of the raw dataframe using
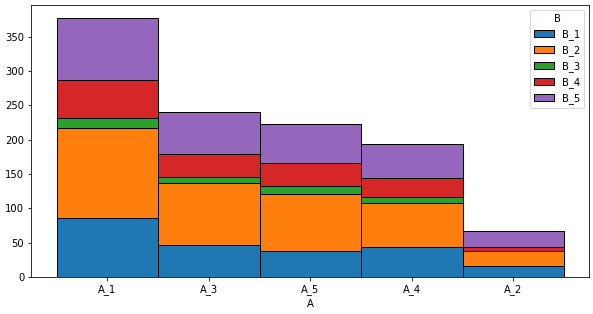
Data Views
dfA B 0 A_5 B_5 1 A_3 B_1 2 A_4 B_5 3 A_3 B_4 4 A_3 B_5dfcB B_1 B_2 B_3 B_4 B_5 tot_A A A_1 86 131 15 55 90 377 A_3 47 90 9 33 61 240 A_5 37 83 13 33 56 222 A_4 43 65 9 27 50 194 A_2 16 21 1 5 24 67CodePudding user response:
You can use below code... you need to get the order that you want the graph sorted (A_1, A_3, ...), then sort your dataframe
df_groupedbefore plotting.#Groupby A and sort by count - send the output as list to ord my_ord = list(df_grouped.groupby(by=['A']).sum().sort_values('count', ascending = False).index) # Order and sort the dataframe so that the final graph is also sorted df_grouped['A'] = pd.Categorical(df_grouped['A'], categories=my_ord, ordered=True) df_grouped = df_grouped.sort_values('A') #Plot graph - no change here fig, ax = plt.subplots(1, 1, figsize=(10,5)) sns.histplot(x='A', hue='B', data=df_grouped, ax=ax, multiple='stack', weights='count')Output