Background:
I have Table 1 with 10,000,000 rows as follows. There are multiple records per ID. The number of records per ID varies.
Table 1
| ID | Start | End |
|---|---|---|
| A | 3 | 5 |
| A | 17 | 21 |
| A | 1 | 10 |
| B | 0 | 5 |
| C | 60 | 70 |
| C | 5 | 55 |
| D | 14 | 24 |
| D | 65 | 100 |
| D | 36 | 49 |
I also have Table 2 with 8,000,000 rows as follows. There are multiple records per ID as well, which also vary. The number of records for a given ID in Table 2 does not have to match the number of records per ID in Table 1 (i.e., there can be fewer entries, the same number of entries, or more entries for the same ID in Table 2 compared with Table 1). In addition, it is possible for Table 2 to have no instances of a given ID in Table 1. For example, Table 2 has no entries for ID D, but has more entries for ID C, compared with Table 1.
Table 2
| ID | Value |
|---|---|
| A | 2 |
| A | 18 |
| B | 0 |
| C | 60 |
| C | 0 |
| C | 4 |
| C | 3 |
Request
I would like to add a new flag column into Table 1. This column takes on values of either 0 or 1. For each row of a given ID in Table 1, it will be compared against all rows for that same ID in Table 2. If any Value in Table 2, for that ID, falls in the range [Start, End] for that specific row and ID in Table 1, then that corresponding row in Table 1 receives a 1. Else, it receives a 0. Each row for a given ID in Table 1 needs to be evaluated separately.
Desired Output (Table 1 Expanded)
| ID | Start | End | FLAG_NEW |
|---|---|---|---|
| A | 3 | 5 | 0 |
| A | 17 | 21 | 1 |
| A | 1 | 10 | 1 |
| B | 0 | 5 | 1 |
| C | 60 | 70 | 1 |
| C | 5 | 55 | 0 |
| D | 14 | 24 | 0 |
| D | 65 | 100 | 0 |
| D | 36 | 49 | 0 |
For example, the first entry for ID A has a range of [3,5] inclusive (Table 1). There are no Values for ID A in Table 2 that fall in this range. Hence, FLAG_NEW=0.
Next, the second entry for ID A has a range of [17, 21]. There is at least one row for ID A in Table 2 that falls in this range (a Value of 18). Hence, FLAG_NEW=1.
I am uncertain how to proceed. I considered doing a left join (many to many match) onto Table 1 based on ID, but this seems untenable given we are dealing with millions of rows and there can be many multiple rows per ID in each table. I have done extensive searching on Stack Overflow but cannot find a post that speaks to this specific use case of multiple entries for a given ID in both tables. 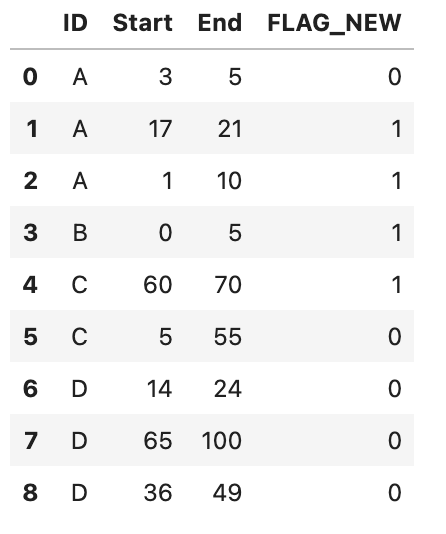
CodePudding user response:
If you're looking to populate a newly-created column:
update table1
set FLAG_NEW = (
select count(distinct 1)
from table2 t2
where t2.ID = table1.ID and t2.Value between table1.Start and table1.End
);