I am trying to merge two dataframes and create a new dataframe containing only the rows from the first dataframe that does not exist in the second one. For example:
The dataframes that I have as input:
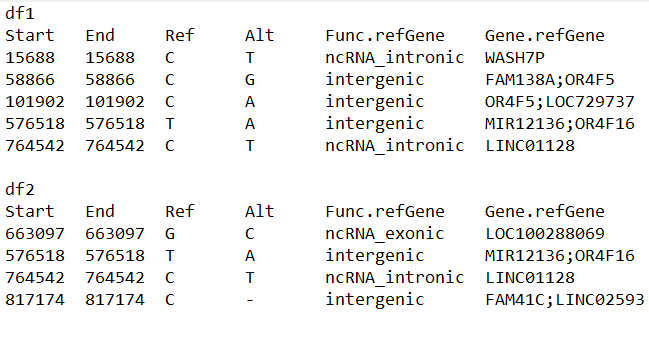
The dataframe that I want to have as output:

Do you know if there is a way to do that? If you could help me, I would be more than thankful!! Thanks, Eleni
CodePudding user response:
Creating some data, we have two dataframes:
import pandas as pd
import numpy as np
rng = np.random.default_rng(seed=5)
df1 = pd.DataFrame(data=rng.integers(0, 5, size=(5, 2)))
df2 = pd.DataFrame(data=rng.integers(0, 5, size=(5, 2)))
# df1
a b
0 3 4
1 0 4
2 2 2
3 3 1
4 4 0
# df2
a b
0 1 1
1 2 2
2 0 0
3 0 0
4 0 4
We can use pandas.merge to combine equal rows. And we can use its indicator=True feature to mark those rows that are only from the left (and right, when applicable). Since we only need those that are unique to left, we can merge using how="left" to be more efficient.
dfm = pd.merge(df1, df2, on=list(df1.columns), how="left", indicator=True)
# dfm
a b _merge
0 3 4 left_only
1 0 4 both
2 2 2 both
3 3 1 left_only
4 4 0 left_only
Great, so then the final result is using the merge
but only keeping those that have an indicator of left_only:
(dfm.loc[dfm._merge == 'left_only']
.drop(columns=['_merge']))
a b
0 3 4
3 3 1
4 4 0
If you'd want to deduplicate by a subset of the columns, that should be possible. In that case I would do the merge it like this, repeating the subset so that we don't get other columns in duplicate versions from the left and right side.
pd.merge(df1, df2[subset], on=subset, how="left", indicator=True)