I am trying to handle the following dataframe
import pandas as pd
df =pd.DataFrame(
data = {'m1' : [0,0,1,0,0,0,0,0,0,0,0],
'm2' : [0,0,0,0,0,1,0,0,0,0,0],
'm3' : [0,0,0,0,0,0,0,0,1,0,0],
'm4' : [0,1,0,0,0,0,0,0,0,0,0],
'm5' : [0,0,0,0,0,0,0,0,0,0,0],
'm6' : [0,0,0,0,0,0,0,0,0,1,0]}
)
df
#
m1 m2 m3 m4 m5 m6
0 0 0 0 0 0 0
1 0 0 0 1 0 0
2 1 0 0 0 0 0
3 0 0 0 0 0 0
4 0 0 0 0 0 0
5 0 1 0 0 0 0
6 0 0 0 0 0 0
7 0 0 0 0 0 0
8 0 0 1 0 0 0
9 0 0 0 0 0 1
10 0 0 0 0 0 0
From the above dataframe, I want to separate m1 and other features.
Assign 1 to m_other if any of m2 to m6 is 1.
Ideal results are shown below.
m1 m_other
0 0 0
1 0 1
2 1 0
3 0 0
4 0 0
5 0 1
6 0 0
7 0 0
8 0 1
9 0 1
10 0 0
I thought about adapting the any function, but I stumbled and couldn't figure it out.
If anyone has any good ideas, I would appreciate it if you could share them with me.
CodePudding user response:
Use 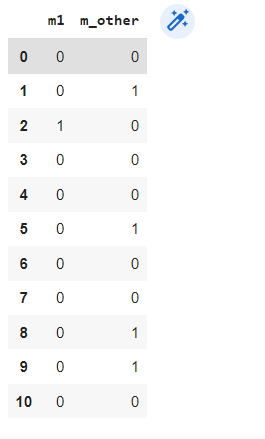
CodePudding user response:
Here is one way to do it using concat to combine the first column and the max of the renaming columns and then renaming the column name
df2=pd.concat([df.iloc[:,:1],(df.iloc[:,1:].max(axis=1))], axis=1)
df2=df2.rename(columns={0:'m_other'})
df2
m1 m_other
0 0 0
1 0 1
2 1 0
3 0 0
4 0 0
5 0 1
6 0 0
7 0 0
8 0 1
9 0 1
10 0 0