I have tried to plot two sets of data in a histogram! the data sets looks like this:
>>> df = load_diffae()
>>> print(df.shape)
(360000, 5)
>>> dfn = load_diffne()
>>> print(dfn.shape)
(360000, 5)
Both have 360000 rows
However, if you look at the histogram, it looks like the new data set has significantly more rows (shown on the Y axis) than the old data set. What could be the reason for this?
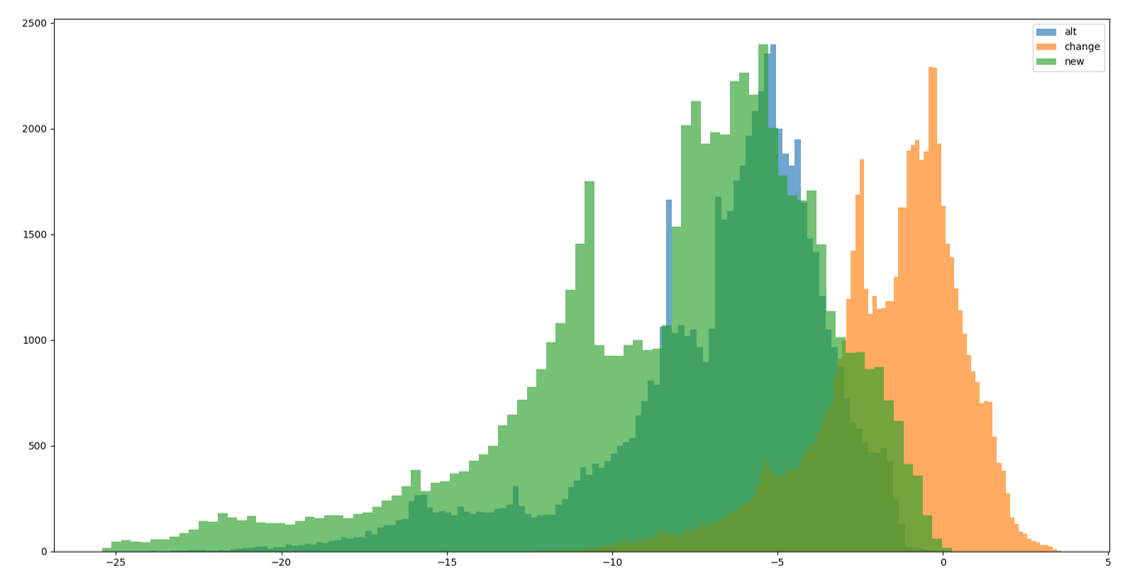
my code:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
from Extract_elevation import *
def load_diffae():
df = dfl
return df
def load_diffd():
dfn = dfld
return dfn
def Plot_show_eu(df,dfd, dfn):
x = dfe['O18ad']
z = dfne['O18nd']
bins = np.linspace(-50, 1, 40)
bins = 'auto'
plt.hist(x, bins, alpha=0.65, label='alt')
plt.hist(z, bins, alpha=0.65, label='new')
plt.legend(loc='upper right')
CodePudding user response:
The bins are chosen differently, so more values enter each bin for larger bins and the plot appears "bigger".