Trying to figure out if I have an R problem or a general neural net problem.
Say I have this data:
set.seed(123)
n = 1e3
x = rnorm(n)
y = 1 3*sin(x/2) 15*cos(pi*x) rnorm(n = length(x))
df = data.frame(y,x)
df$train = sample(c(TRUE, FALSE), length(y), replace=TRUE, prob=c(0.7,0.3))
df_train = subset(df, train = TRUE)
df_test = subset(df, train = FALSE)
then you train the neural net and it looks good on the holdout:
library(nnet)
nn = nnet(y~x, data = df_train, size = 60, linout=TRUE)
yhat_nn = predict(nn, newdata = df_test)
plot(df_test$x,df_test$y)
points(df_test$x, yhat_nn, col = 'blue')
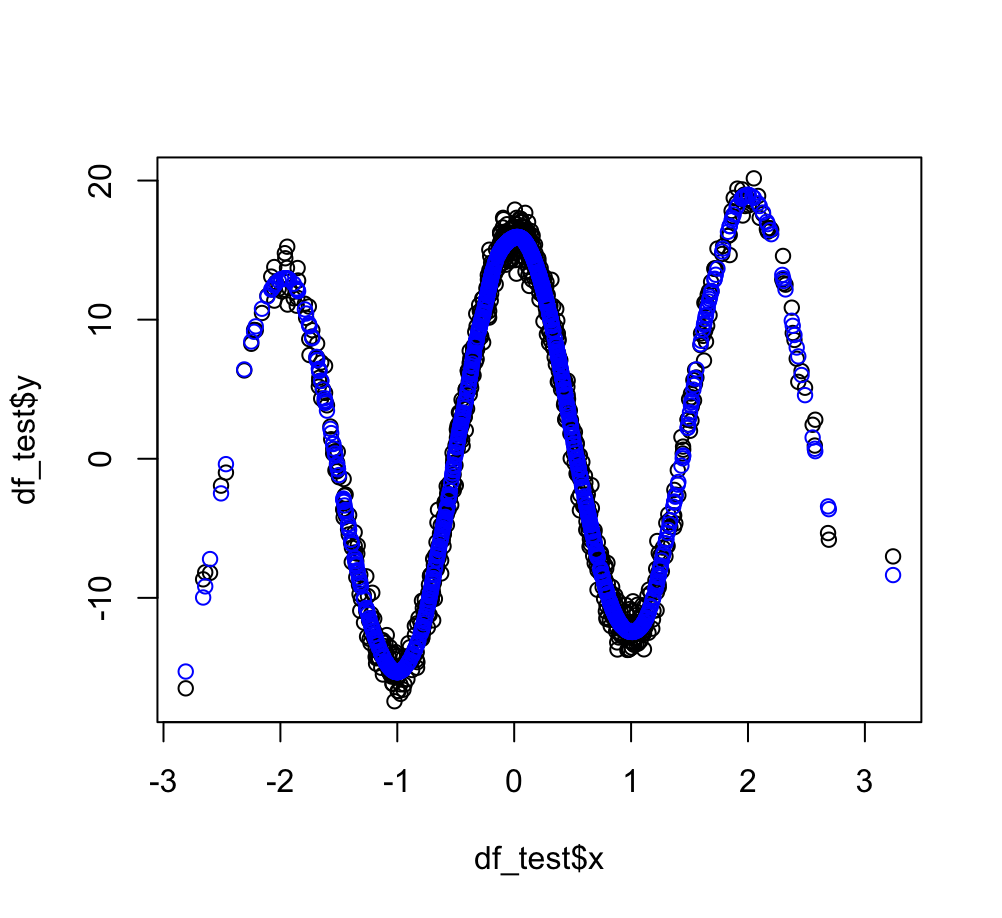
Ok, so then I thought, let's just generate new data and then predict using the trained net. But the predictions are way off:
x2 = rnorm(n)
y2 = 1 3*sin(x2/2) 15*cos(pi*x2) rnorm(n = length(x2))
df2 = data.frame(y2,x2)
plot(df2$x, df2$y)
points(df2$x, predict(nn, newdata = df2), col = 'blue')
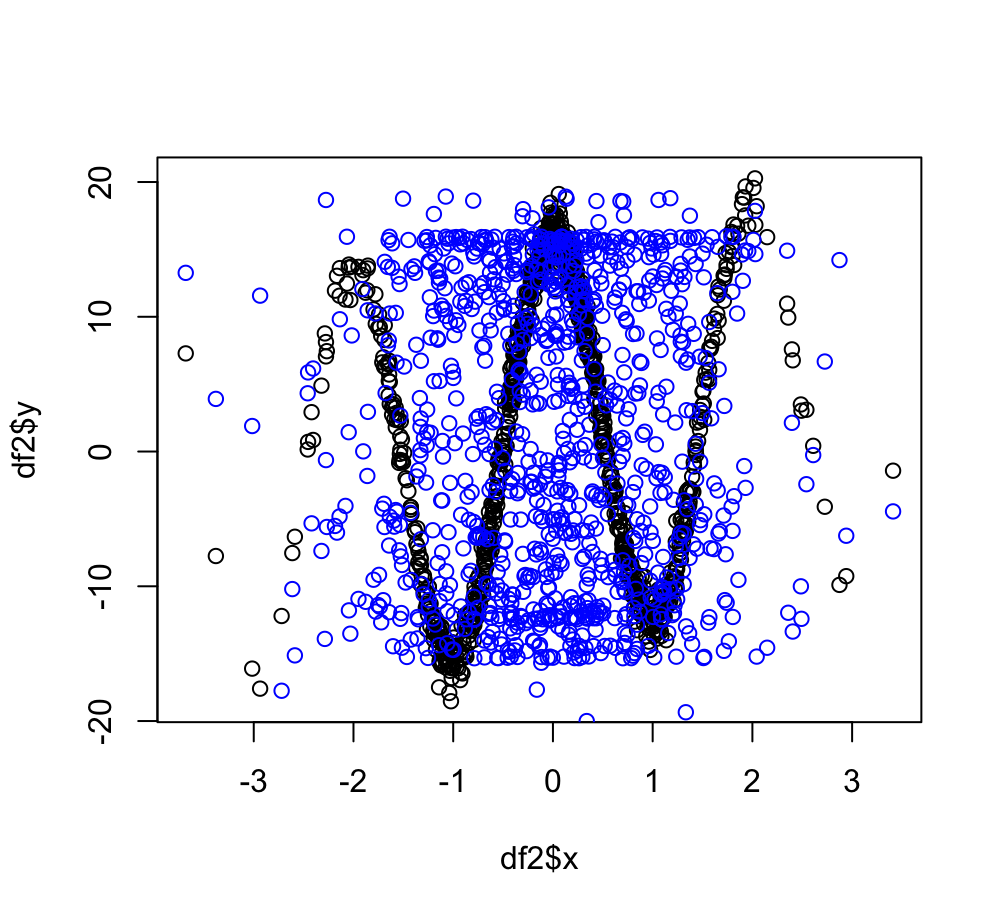
Is this because I overfitted to the training set? I thought by splitting the original data into test-train I would avoid overfitting.
CodePudding user response:
The fatal issue is that your new data frame, df2, does not have the correct variable names. As a result, predict.nnet can not find the right values.
names(df)
#[1] "y" "x" "train"
names(df2)
#[1] "y2" "x2"
Be careful when you construct a data frame for predict.
## the right way
df2 <- data.frame(y = y2, x = x2)
## and it solves the mystery
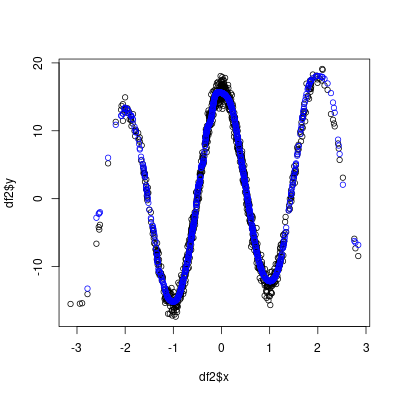
plot(df2$x, df2$y)
points(df2$x, predict(nn, newdata = df2), col = 'blue')
Another minor issue is your use of subset. It should be
## not train = TRUE or train = FALSE
df_train <- subset(df, train == TRUE) ## or simply subset(df, train)
df_test <- subset(df, train == FALSE) ## or simply subset(df, !train)
This has interesting effect:
nrow(subset(df, train == TRUE))
#[1] 718
nrow(subset(df, train = TRUE)) ## oops!!
#[1] 1000
The complete R session
set.seed(123)
n = 1e3
x = rnorm(n)
y = 1 3*sin(x/2) 15*cos(pi*x) rnorm(n = length(x))
df = data.frame(y,x)
df$train = sample(c(TRUE, FALSE), length(y), replace=TRUE, prob=c(0.7,0.3))
df_train = subset(df, train == TRUE) ## fixed
df_test = subset(df, train == FALSE) ## fixed
library(nnet)
nn = nnet(y~x, data = df_train, size = 60, linout=TRUE)
yhat_nn = predict(nn, newdata = df_test)
plot(df_test$x,df_test$y)
points(df_test$x, yhat_nn, col = 'blue')
x2 = rnorm(n)
y2 = 1 3*sin(x2/2) 15*cos(pi*x2) rnorm(n = length(x2))
df2 = data.frame(y = y2, x = x2) ## fixed
plot(df2$x, df2$y)
points(df2$x, predict(nn, newdata = df2), col = 'blue')